Capítulo 7 As Classes Básicas de Objetos
As classes básicas são os elementos mais primários na representação de dados no R. Nos capítulos anteriores utilizamos as classes básicas como colunas em uma tabela. Dados numéricos viraram uma coluna do tipo numeric, enquanto dados de texto viraram um objeto do tipo character.
Neste capítulo iremos estudar mais a fundo as classes básicas de objetos do R, incluindo a sua criação até a manipulação do seu conteúdo. Este capítulo é de suma importância pois mostrará quais operações são possíveis com cada classe de objeto e como podes manipular as informações de forma eficiente. Os tipos de objetos tratados aqui serão:
- Numéricos (
numeric) - Texto (
character) - Fatores (
factor) - Valores lógicos (
logical) - Datas e tempo (
Dateetimedate) - Dados Omissos (
NA)
7.1 Objetos Numéricos
Uma das classes mais utilizadas em pesquisa empírica. Os valores numéricos são representações de uma quantidade. Por exemplo: o preço de uma ação em determinada data, o volume negociado de um contrato financeiro em determinado dia, a inflação anual de um país, entre várias outras possibilidades.
7.1.1 Criando e Manipulando Vetores Numéricos
A criação e manipulação de valores numéricos é fácil e direta. Os símbolos de operações matemáticas seguem o esperado, tal como soma (+), diminuição (-), divisão (/) e multiplicação (*). Todas as operações matemáticas são efetuadas com a orientação de elemento para elemento e possuem notação vetorial. Isso significa, por exemplo, que podemos manipular vetores inteiros em uma única linha de comando. Veja a seguir, onde se cria dois vetores e realiza-se diversas operações entre eles.
# create numeric vectors
x <- 1:5
y <- 2:6
# print sum
print(x+y)R> [1] 3 5 7 9 11# print multiplication
print(x*y)R> [1] 2 6 12 20 30# print division
print(x/y)R> [1] 0.5000000 0.6666667 0.7500000 0.8000000 0.8333333# print exponentiation
print(x^y)R> [1] 1 8 81 1024 15625Um diferencial do R em relação a outras linguagens é que, nele, são aceitas operações entre vetores diferentes. Por exemplo, podemos somar um vetor numérico de quatro elementos com outro de apenas dois. Nesse caso, aplica-se a chamada regra de reciclagem (recycling rule). Ela define que, se dois vetores de tamanho diferente estão interagindo, o vetor menor é repetido tantas vezes quantas forem necessárias para obter-se o mesmo número de elementos do vetor maior. Veja o exemplo a seguir:
# set x with 4 elements and y with 2
x <- 1:4
y <- 2:1
# print sum
print(x + y)R> [1] 3 3 5 5O resultado de x + y é equivalente a 1:4 + c(2, 1, 2, 1). Caso interagirmos vetores em que o tamanho do maior não é múltiplo do menor, o R realiza o mesmo procedimento de reciclagem, porém emite uma mensagem de warning:
# set x = 4 elements and y with 3
x <- c(1, 2, 3, 4)
y <- c(1, 2, 3)
# print sum (recycling rule)
print(x +y)R> Warning in x + y: longer object length is not a multiple of
R> shorter object lengthR> [1] 2 4 6 5Os três primeiros elementos de x foram somados aos três primeiros elementos de y. O quarto elemento de x foi somado ao primeiro elemento de y. Uma vez que não havia um quarto elemento em y, o ciclo reinicia, resgatando o primeiro elemento de y e resultando em uma soma igual a 5.
Os elementos de um vetor numérico também podem ser nomeados quando na criação do vetor:
R> item1 item2 item3 item4
R> 10 14 9 2Para nomear os elementos após a criação, podemos utilizar a função names. Veja a seguir:
# create unnamed vector
x <- c(10, 14, 9, 2)
# set names of elements
names(x) <- c('item1', 'item2', 'item3', 'item4')
# print it
print(x)R> item1 item2 item3 item4
R> 10 14 9 2Vetores numéricos vazios também podem ser criados. Em algumas situações de desenvolvimento de código faz sentido pré-alocar o vetor antes de preenchê-lo com valores. Nesse caso, utilize a função numeric:
R> [1] 0 0 0 0 0 0 0 0 0 0Observe que, nesse caso, os valores de my_x são definidos como zero.
7.1.1.1 Criando Sequências de Valores
Existem duas maneiras de criar uma sequência de valores no R. A primeira, que já foi utilizada nos exemplos anteriores, é o uso do operador :. Por exemplo, my_seq <- 1:10 ou my_seq <- -5:5. Esse método é bastante prático, pois a notação é clara e direta.
Porém, o uso do operador : limita as possibilidades. A diferença entre os valores adjacentes é sempre 1 para sequências ascendentes e -1 para sequências descendentes. Uma versão mais poderosa para a criação de sequências é o uso da função seq. Com ela, é possível definir os intervalos entre cada valor com o argumento by. Veja a seguir:
R> [1] -10 -8 -6 -4 -2 0 2 4 6 8 10Outro atributo interessante da função seq é a possibilidade de criar vetores com um valor inicial, um valor final e o número de elementos desejado. Isso é realizado com o uso da opção length.out. Observe o código a seguir, onde cria-se um vetor de 0 até 10 com 20 elementos:
# set sequence with fixed size
my_seq <- seq(from = 0, to = 10, length.out = 20)
# print it
print(my_seq)R> [1] 0.0000000 0.5263158 1.0526316 1.5789474 2.1052632
R> [6] 2.6315789 3.1578947 3.6842105 4.2105263 4.7368421
R> [11] 5.2631579 5.7894737 6.3157895 6.8421053 7.3684211
R> [16] 7.8947368 8.4210526 8.9473684 9.4736842 10.0000000No caso anterior, o tamanho final do vetor foi definido e a própria função se encarregou de descobrir qual a variação necessária entre cada valor de my_seq.
7.1.1.2 Criando Vetores com Elementos Repetidos
Outra função interessante é a que cria vetores com o uso de repetição. Por exemplo: imagine que estamos interessado em um vetor preenchido com o valor 1 dez vezes. Para isso, basta utilizar a função rep:
R> [1] 1 1 1 1 1 1 1 1 1 1A função também funciona com vetores. Considere uma situação onde temos um vetor com os valores c(1,2) e gostaríamos de criar um vetor maior com os elementos c(1, 2, 1, 2, 1, 2) - isto é, repetindo o vetor menor três vezes. Veja o resultado a seguir:
R> [1] 1 2 1 2 1 27.1.1.3 Criando Vetores com Números Aleatórios
Em muitas situações será necessário a criação de números aleatórios. Esse procedimento numérico é bastante utilizado para simular modelos matemáticos em Finanças. Por exemplo, o método de simulação de preços de ativos de Monte Carlo parte da simulação de números aleatórios (McLeish 2011). No R, existem diversas funções que criam números aleatórios para diferentes distribuições estatísticas. As mais utilizadas, porém, são as funções rnorm e runif.
A função rnorm gera números aleatórios da distribuição Normal, com opções para a média (tendência) e o desvio padrão (variabilidade). Veja o seu uso a seguir:
# generate 10000 random numbers from a Normal distribution
my_rnd_vec <- rnorm(n = 10000,
mean = 0,
sd = 1)
# print first 20 elements
print(my_rnd_vec[1:20])R> [1] 2.23119099 1.05644632 -1.71152285 0.08969915
R> [5] 0.53618561 -1.18846705 0.49985211 0.24460369
R> [9] -1.38991172 -2.18683422 0.11774128 0.59345327
R> [13] 0.76478439 -1.73273109 0.18912067 1.44049229
R> [17] 1.05879799 0.80602246 -1.80066481 0.84976441O código anterior gera uma grande quantidade de números aleatórios de uma distribuição Normal com média zero e desvio padrão igual a um. Podemos verificar a distribuição dos números gerados com um histograma:
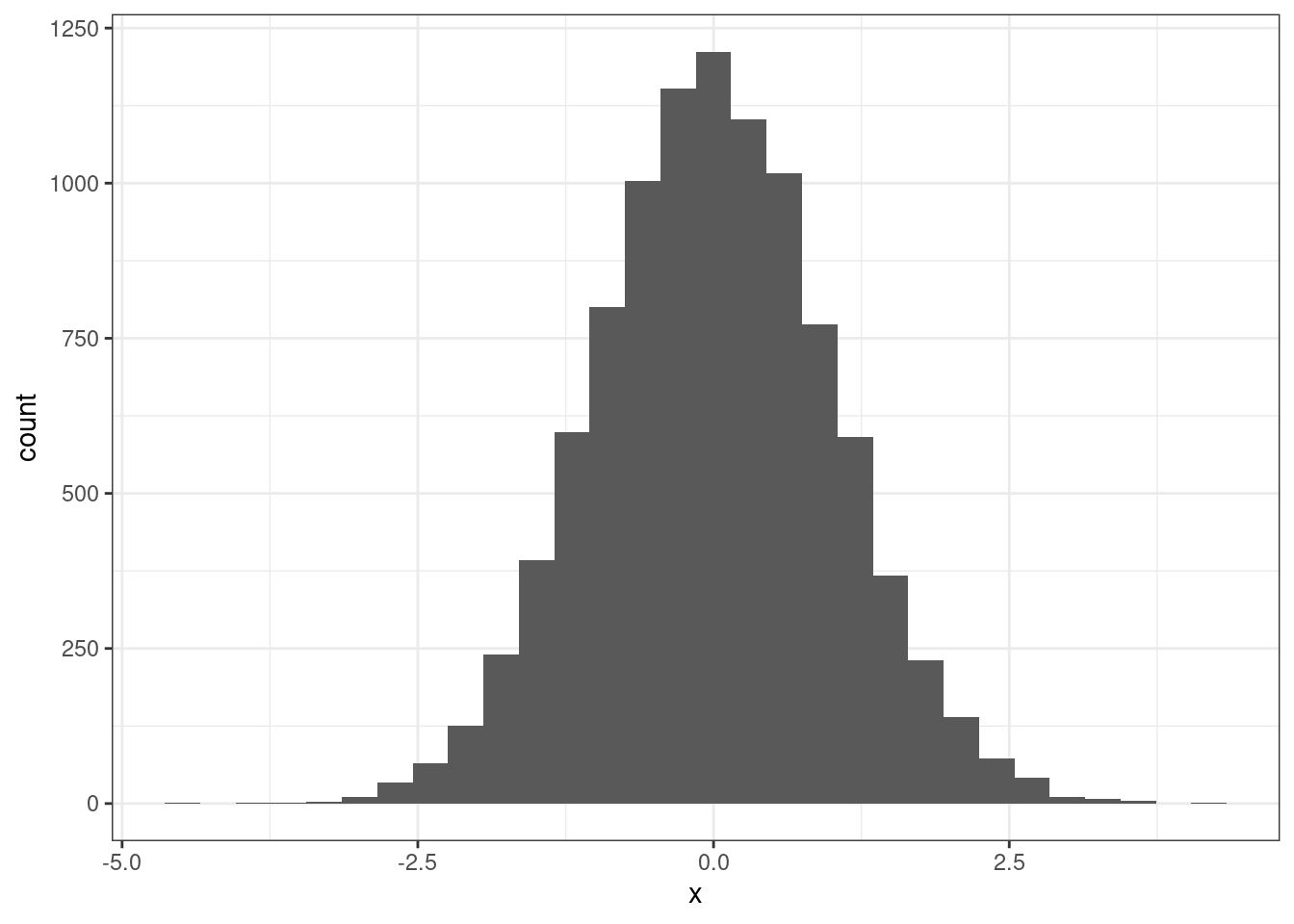
Como esperado, temos o formato de sino que caracteriza uma distribuição do tipo Normal. Como exercício, podes trocar as entradas mean e sd e confirmar como isso afeta a figura gerada.
Já a função runif gera valores aleatórios da distribuição uniforme entre um valor máximo e um valor mínimo. Ela é geralmente utilizada para simular probabilidades. A função runif tem três parâmetros de entrada: o número de valores aleatórios desejado, o valor mínimo e o valor máximo. Veja exemplo a seguir:
# create a random vector with minimum and maximum
my_rnd_vec <- runif(n = 10,
min = -5,
max = 5)
# print it
print(my_rnd_vec)R> [1] -1.6703200 -0.2582507 2.4043159 3.4723961 0.6118807
R> [6] -4.4737420 -2.8958942 -4.1903425 -2.2709078 -3.1077450Observe que ambas as funções anteriores são limitadas à sua respectiva distribuição. Uma maneira alternativa e flexível de gerar valores aleatórios é utilizar a função sample. Essa tem como entrada um vetor qualquer e retorna uma versão embaralhada de seus elementos. A sua flexibilidade reside no fato de que o vetor de entrada pode ser qualquer coisa. Por exemplo, caso quiséssemos criar um vetor aleatório com os números c(0, 5, 15, 20, 25) apenas, poderíamos fazê-lo da seguinte forma:
# create sequence
my_vec <- seq(from = 0, to = 25, by=5)
# sample sequence
my_rnd_vec <- sample(my_vec)
# print it
print(my_rnd_vec)R> [1] 0 5 20 25 15 10A função sample também permite a seleção aleatória de um certo número de termos. Por exemplo, caso quiséssemos selecionar aleatoriamente apenas um elemento de my_vec, escreveríamos o código da seguinte maneira:
R> [1] 10Caso quiséssemos dois elementos, escreveríamos:
R> [1] 0 20Também é possível selecionar valores de uma amostra menor para a criação de um vetor maior. Por exemplo, considere o caso em que se tem um vetor com os números c(10, 15, 20) e deseja-se criar um vetor aleatório com dez elementos retirados desse vetor menor, com repetição. Para isso, podemos utilizar a opção replace = TRUE.
# create vector
my_vec <- c(5, 10, 15)
# sample
my_rnd_vec <- sample(x = my_vec, size = 10, replace = TRUE)
print(my_rnd_vec)R> [1] 10 10 10 10 5 5 10 15 15 5Vale destacar que a função sample funciona para qualquer tipo ou objeto, não sendo, portanto, exclusiva para vetores numéricos. Poderíamos, também, escolher elementos aleatórios de um vetor de texto ou então uma lista:
R> [1] "elem 3"R> $y
R> [1] "a" "b"É importante ressaltar que a geração de valores aleatórios no R (ou qualquer outro programa) não é totalmente aleatória! De fato, o próprio computador escolhe os valores dentre uma fila de valores possíveis. Cada vez que funções tal como rnorm, runif e sample são utilizadas, o computador escolhe um lugar diferente dessa fila de acordo com vários parâmetros, incluindo a data e horário atual. Portanto, do ponto de vista do usuário, os valores são gerados de forma imprevisível. Para o computador, porém, essa seleção é completamente determinística e guiada por regras claras.
Uma propriedade interessante no R é a possibilidade de selecionar uma posição específica na fila de valores aleatórios utilizando função set.seed. É ela que fixa a semente para gerar os valores. Na prática, o resultado é que todos os números e seleções aleatórias realizadas pelo código serão iguais em cada execução. O uso de set.seed é bastante recomendado para manter a reprodutibilidade dos códigos envolvendo aleatoriedade. Veja o exemplo a seguir, onde utiliza-se essa função.
R> [1] 0.50747820 0.30676851 0.42690767 0.69310208 0.08513597R> [1] 0.2254366 0.2745305 0.2723051 0.6158293 0.4296715No código anterior, o valor de set.seed é um inteiro escolhido pelo usuário. Após a chamada de set.seed, todas as seleções e números aleatórios irão iniciar do mesmo ponto e, portanto, serão iguais. Motivo o leitor a executar o código anterior no R. Verás que os valores de my_rnd_vec_1 e my_rnd_vec_2 serão exatamente iguais aos valores colocados aqui.
O uso de set.seed também funciona para o caso de sample. Veja a seguir:
R> [1] 5 2 1 6 8 10 3 7 9 4R> [1] 13 15 10 17 20 14 19 12 11 18 16Novamente, execute os comandos anteriores no R e verás que o resultado na tela bate com o apresentado aqui.
7.1.2 Acessando Elementos de um Vetor Numérico
Todos os elementos de um vetor numérico podem ser acessados através do uso de colchetes ([ ]). Por exemplo, caso quiséssemos apenas o primeiro elemento de x, teríamos:
# set vector
x <- c(-1, 4, -9, 2)
# get first element
first_elem_x <- x[1]
# print it
print(first_elem_x)R> [1] -1A mesma notação é válida para extrair porções de um vetor. Caso quiséssemos um subvetor de x com o primeiro e o segundo elemento, faríamos essa operação da seguinte forma:
# sub-vector of x
sub_x <- x[1:2]
# print it
print(sub_x)R> [1] -1 4Para acessar elementos nomeados de um vetor numérico, basta utilizar seu nome junto aos colchetes.
# set named vector
x <- c(item1 = 10, item2 = 14, item3 = -9, item4 = -2)
# access elements by name
print(x['item2'])R> item2
R> 14R> item2 item4
R> 14 -2O acesso aos elementos de um vetor numérico também é possível através de testes lógicos. Por exemplo, caso tivéssemos interesse em saber quais os valores de x que são maiores do que 0, o código resultante seria da seguinte forma:
# find all values of x higher than zero
print(x[x > 0])R> item1 item2
R> 10 14Os usos de regras de segmentação dos dados de acordo com algum critério é chamado de indexação lógica. Os objetos do tipo logical serão tratados mais profundamente em seção futura deste capítulo.
7.1.3 Modificando e Removendo Elementos de um Vetor Numérico
A modificação de um vetor numérico é muito simples. Basta indicar a posição dos elementos e os novos valores com o símbolo de assign (<-):
# set vector
my_x <- 1:4
# modify first element to 5
my_x[1] <- 5
# print result
print(my_x)R> [1] 5 2 3 4Essa modificação também pode ser realizada em bloco:
# set vector
my_x <- 0:5
# set the first three elements to 5
my_x[1:3] <- 5
# print result
print(my_x)R> [1] 5 5 5 3 4 5O uso de condições para definir elementos é realizada pela indexação:
# set vector
my_x <- -5:5
# set any value lower than 2 to 0
my_x[my_x<2] <- 0
# print result
print(my_x)R> [1] 0 0 0 0 0 0 0 2 3 4 5A remoção de elementos é realizada com o uso de índices negativos:
# create vector
my_x <- -5:5
# remove first and second element of my_x
my_x <- my_x[-(1:2)]
# show result
print(my_x)R> [1] -3 -2 -1 0 1 2 3 4 5Note como o uso do índice negativo em my_x[-(1:2)] retorna o vetor original sem o primeiro e segundo elemento.
7.1.4 Criando Grupos
Em algumas situações será necessário entender quantos casos da amostra estão localizados entre um determinado intervalo. Por exemplo, imagine o vetor dos retornos diários de uma ação, isto é, a variação percentual dos preços de fechamento entre um dia e outro. Uma possível análise de risco que pode ser realizada é dividir o intervalo de retornos em cinco partes e verificar o percentual de ocorrência dos valores em cada um dos intervalos. Essa análise numérica é bastante semelhante à construção e visualização de histogramas.
A função cut serve para criar grupos de intervalos a partir de um vetor numérico. Veja o exemplo a seguir, onde cria-se um vetor aleatório oriundo da distribuição Normal e cinco grupos a partir de intervalos definidos pelos dados.
# set rnd vec
my_x <- rnorm(10)
# "cut" it into 5 pieces
my_cut <- cut(x = my_x, breaks = 5)
print(my_cut)R> [1] (-1.57,-1.12] (0.252,0.71] (-1.12,-0.66]
R> [4] (-0.204,0.252] (-0.66,-0.204] (-1.57,-1.12]
R> [7] (0.252,0.71] (-0.204,0.252] (0.252,0.71]
R> [10] (-0.204,0.252]
R> 5 Levels: (-1.57,-1.12] (-1.12,-0.66] ... (0.252,0.71]Observe que os nomes dos elementos da variável my_cut são definidos pelos intervalos e o resultado é um objeto do tipo fator. Em seções futuras, iremos explicar melhor esse tipo de objeto e as suas propriedades.
No exemplo anterior, os intervalos para cada grupo foram definidos automaticamente. No uso da função cut, também é possível definir quebras customizadas nos dados e nos nomes dos grupos. Veja a seguir:
# set random vector
my_x <- rnorm(10)
# create groups with 5 breaks
my_cut <- cut(x = my_x, breaks = 5)
# print it!
print(my_cut)R> [1] (-1.3,-0.3] (-0.3,0.697] (-0.3,0.697] (-2.3,-1.3]
R> [5] (-0.3,0.697] (0.697,1.69] (0.697,1.69] (0.697,1.69]
R> [9] (-1.3,-0.3] (1.69,2.7]
R> 5 Levels: (-2.3,-1.3] (-1.3,-0.3] ... (1.69,2.7]Note que os nomes dos elementos em my_cut foram definidos como intervalos e o resultado é um objeto do tipo fator. É possível também definir intervalos e nomes customizados para cada grupo com o uso dos argumentos labels e breaks:
# create random vector
my_x <- rnorm(10)
# define breaks manually
my_breaks <- c(min(my_x)-1, -1, 1, max(my_x)+1)
# define labels manually
my_labels <- c('Low','Normal', 'High')
# create group from numerical vector
my_cut <- cut(x = my_x, breaks = my_breaks, labels = my_labels)
# print both!
print(my_x)R> [1] 0.5981759 1.6113647 -0.4373813 1.3526206 0.4705685
R> [6] 0.4702481 0.3963088 -0.7304926 0.6531176 1.2279598print(my_cut)R> [1] Normal High Normal High Normal Normal Normal Normal
R> [9] Normal High
R> Levels: Low Normal HighComo podemos ver, os nomes dos grupos estão mais amigáveis para uma futura análise.
7.1.5 Outras Funções Úteis
as.numeric - Converte determinado objeto para numérico.
R> [1] "character"my_x <- as.numeric(my_text)
print(my_x)R> [1] 1 2 3class(my_x)R> [1] "numeric"sum - Soma os elementos de um vetor.
R> [1] 1275max - Retorna o máximo valor numérico do vetor.
R> [1] 14min - Retorna o mínimo valor numérico do vetor.
R> [1] 2which.max - Retorna a posição do máximo valor numérico do vetor.
x <- c(100, 141, 9, 2)
which.max_x <- which.max(x)
cat(paste('The position of the maximum value of x is ', which.max_x))R> The position of the maximum value of x is 2cat(' and its value is ', x[which.max_x])R> and its value is 141which.min - Retorna a posição do mínimo valor numérico do vetor.
x <- c(10, 14, 9, 2)
which.min_x <- which.min(x)
cat(paste('The position of the minimum value of x is ',
which.min_x, ' and its value is ', x[which.min_x]))R> The position of the minimum value of x is 4 and its value is 2sort - Retorna uma versão ordenada de um vetor.
R> [1] 0.1623069 0.8347800 0.8553657 0.9099027 0.9935257R> [1] 0.9935257 0.9099027 0.8553657 0.8347800 0.1623069cumsum - Soma os elementos de um vetor de forma cumulativa.
R> [1] 1 3 6 10 15 21 28 36 45 55 66 78 91 105
R> [15] 120 136 153 171 190 210 231 253 276 300 325prod - Realiza o produto de todos os elementos de um vetor.
R> [1] 3628800cumprod - Calcula o produto cumulativo de todos os elementos de um vetor.
R> [1] 1 2 6 24 120 720 5040
R> [8] 40320 362880 36288007.2 Classe de Caracteres (texto)
A classe de caracteres, ou texto, serve para armazenar informações textuais. Um exemplo prático em Finanças seria o reconhecimento de uma ação através dos seus símbolos de identificação (tickers) ou então por sua classe de ação: ordinária ou preferencial. Este tipo de dado tem sido utilizado cada vez mais em pesquisa empírica (Gentzkow, Kelly, and Taddy 2017), resultando em uma diversidade de pacotes.
O R possui vários recursos que facilitam a criação e manipulação de objetos de tipo texto. As funções básicas fornecidas com a instalação de R são abrangentes e adequadas para a maioria dos casos. No entanto, pacote stringr (Wickham 2022b) do tidyverse fornece muitas funções que expandem a funcionalidade básica do R na manipulação de texto.
Um aspecto positivo de stringr é que as funções começam com o nome str_ e possuem nomes informativos. Combinando isso com o recurso de preenchimento automático (autocomplete) pela tecla tab, fica fácil de localizar os nomes das funções do pacote. Seguindo a prioridade ao universo do tidyverse, esta seção irá dar preferência ao uso das funções do pacote stringr. As rotinas nativas de manipulação de texto serão apresentadas, porém de forma limitada.
7.2.1 Criando um Objeto Simples de Caracteres
Todo objeto de caracteres é criado através da encapsulação de um texto por aspas duplas (" ") ou simples (' '). Para criar um vetor de caracteres com tickers de ações, podemos fazê-lo com o seguinte código:
R> [1] "PETR3" "VALE4" "GGBR4"Confirma-se a classe do objeto com a função class:
class(my_assets)R> [1] "character"7.2.2 Criando Objetos Estruturados de Texto
Em muitos casos no uso do R, estaremos interessados em criar vetores de texto com algum tipo de estrutura própria. Por exemplo, o vetor c("text 1", "text 2", ..., "text 20") possui um lógica de criação clara. Computacionalmente, podemos definir a sua estrutura como sendo a junção do texto text e um vetor de sequência, de 1 até 20.
Para criar um vetor textual capaz de unir texto com número, utilizamos a função stringr::str_c ou base::paste. Veja o exemplo a seguir, onde replica-se o caso anterior com e sem espaço entre número e texto:
library(stringr)
# create sequence
my_seq <- 1:20
# create character
my_text <- 'text'
# paste objects together (without space)
my_char <- str_c(my_text, my_seq)
print(my_char)R> [1] "text1" "text2" "text3" "text4" "text5" "text6"
R> [7] "text7" "text8" "text9" "text10" "text11" "text12"
R> [13] "text13" "text14" "text15" "text16" "text17" "text18"
R> [19] "text19" "text20"R> [1] "text 1" "text 2" "text 3" "text 4" "text 5"
R> [6] "text 6" "text 7" "text 8" "text 9" "text 10"
R> [11] "text 11" "text 12" "text 13" "text 14" "text 15"
R> [16] "text 16" "text 17" "text 18" "text 19" "text 20"R> [1] "text 1" "text 2" "text 3" "text 4" "text 5"
R> [6] "text 6" "text 7" "text 8" "text 9" "text 10"
R> [11] "text 11" "text 12" "text 13" "text 14" "text 15"
R> [16] "text 16" "text 17" "text 18" "text 19" "text 20"O mesmo procedimento também pode ser realizado com vetores de texto. Veja a seguir:
# set character value
my_x <- 'My name is'
# set character vector
my_names <- c('Marcelo', 'Ricardo', 'Tarcizio')
# paste and print
print(str_c(my_x, my_names, sep = ' '))R> [1] "My name is Marcelo" "My name is Ricardo"
R> [3] "My name is Tarcizio"Outra possibilidade de construção de textos estruturados é a repetição do conteúdo de um objeto do tipo caractere. No caso de texto, utiliza-se a função stringr::str_dup/base::strrep para esse fim. Observe o exemplo a seguir:
R> [1] "abcabcabcabcabc"7.2.3 Objetos Constantes de Texto
O R também possibilita o acesso direto a todas as letras do alfabeto. Esses estão guardadas nos objetos reservados chamados letters e LETTERS:
# print all letters in alphabet (no cap)
print(letters)R> [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n"
R> [15] "o" "p" "q" "r" "s" "t" "u" "v" "w" "x" "y" "z"# print all letters in alphabet (WITH CAP)
print(LETTERS)R> [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N"
R> [15] "O" "P" "Q" "R" "S" "T" "U" "V" "W" "X" "Y" "Z"Observe que em ambos os casos não é necessário criar os objetos. Por serem constantes embutidas automaticamente na área de trabalho do R, elas já estão disponíveis para uso. Podemos sobrescrever o nome do objeto com outro conteúdo, porém isso não é aconselhável. Nunca se sabe onde esse objeto constante está sendo usado. Outros objetos de texto constantes no R incluem month.abb e month.name. Veja a seguir o seu conteúdo:
# print abreviation and full names of months
print(month.abb)R> [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep"
R> [10] "Oct" "Nov" "Dec"print(month.name)R> [1] "January" "February" "March" "April"
R> [5] "May" "June" "July" "August"
R> [9] "September" "October" "November" "December"7.2.4 Selecionando Pedaços de um Texto
Um erro comum praticado por iniciantes é tentar selecionar pedaços de um texto através do uso de colchetes. Observe o código abaixo:
# set char object
my_char <- 'ABCDE'
# print its second character: 'B' (WRONG - RESULT is NA)
print(my_char[2])R> [1] NAO resultado NA indica que o segundo elemento de my_char não existe. Isso acontece porque o uso de colchetes refere-se ao acesso de elementos de um vetor atômico, e não de caracteres dentro de um texto maior. Observe o que acontece quando utilizamos my_char[1]:
print(my_char[1])R> [1] "ABCDE"O resultado é simplesmente o texto ABCDE, que está localizado no primeiro item de my_char. Para selecionar pedaços de um texto, devemos utilizar a função específica stringr::str_sub/base::substr:
# print third and fourth characters
my_substr <- str_sub(string = my_char,
start = 4,
end = 4)
print(my_substr)R> [1] "D"Essa função também funciona para vetores atômicos. Vamos assumir que você importou dados de texto e o conjunto de dados bruto contém um identificador de 3 dígitos de uma empresa, sempre na mesma posição do texto. Vamos simular a situação no R:
# build char vec
my_char_vec <- paste0(c('123','231','321'),
' - other ignorable text')
print(my_char_vec)R> [1] "123 - other ignorable text"
R> [2] "231 - other ignorable text"
R> [3] "321 - other ignorable text"Só estamos interessados na informação das três primeiras letras de cada elemento em my_char_vec. Para selecioná-los, podemos usar as mesmas funções que antes.
R> [1] "123" "231" "321"Operações vetorizadas são comuns e esperadas no R. Quase tudo o que você pode fazer para um único elemento pode ser expandido para vetores. Isso facilita o desenvolvimento de rotinas pois pode-se facilmente realizar tarefas complicadas em uma série de elementos, em uma única linha de código.
7.2.5 Localizando e Substituindo Pedaços de um Texto
Uma operação útil na manipulação de textos é a localização de letras e padrões específicos com funções stringr::str_locate/base::regexpr e stringr::str_locate_all/base::gregexpr. É importante destacar que, por default, essas funções utilizam de expressões do tipo regex - expressões regulares (Thompson 1968). Essa é uma linguagem específica para processar textos. Diversos símbolos são utilizados para estruturar, procurar e isolar padrões textuais. Quando utilizada corretamente, o regex é bastante útil e de extrema valia.
Usualmente, o caso mais comum em pesquisa é verificar a posição ou a existência de um texto menor dentro de um texto maior. Isto é, um padrão explícito e fácil de entender. Por isso, a localização e substituição de caracteres no próximo exemplo será do tipo fixo, sem o uso de regex. Tal informação pode ser passada às funções do pacote stringr através de outra função chamada stringr::fixed.
O exemplo a seguir mostra como encontrar o caractere D dentre uma série de caracteres.
library(stringr)
my_char <- 'ABCDEF-ABCDEF-ABC'
pos = str_locate(string = my_char, pattern = fixed('D') )
print(pos)R> start end
R> [1,] 4 4Observe que a função str_locate retorna apenas a primeira ocorrência de D. Para resgatar todas as ocorrências, devemos utilizar a função str_locate_all:
# set object
my_char <- 'ABCDEF-ABCDEF-ABC'
# find position of ALL 'D' using str_locate_all
pos = str_locate_all(string = my_char, pattern = fixed('D'))
print(pos)R> [[1]]
R> start end
R> [1,] 4 4
R> [2,] 11 11Observe também que as funções regexp e grepexpr retornam objetos com propriedades específicas, apresentando-as na tela.
Para substituir caracteres em um texto, basta utilizar a função stringr::str_replace ou base::sub e str_replace_all ou base::gsub. Vale salientar que str_replace substitui a primeira ocorrência do caractere, enquanto str_replace_all executa uma substituição global - isto é, aplica-se a todas as ocorrências. Veja a diferença a seguir:
# set char object
my_char <- 'ABCDEF-ABCDEF-ABC'
# substitute the FIRST 'ABC' for 'XXX' with sub
my_char <- sub(x = my_char,
pattern = 'ABC',
replacement = 'XXX')
print(my_char)R> [1] "XXXDEF-ABCDEF-ABC"# substitute the FIRST 'ABC' for 'XXX' with str_replace
my_char <- 'ABCDEF-ABCDEF-ABC'
my_char <- str_replace(string = my_char,
pattern = fixed('ABC'),
replacement = 'XXX')
print(my_char)R> [1] "XXXDEF-ABCDEF-ABC"E agora fazemos uma substituição global dos caracteres.
# set char object
my_char <- 'ABCDEF-ABCDEF-ABC'
# substitute the FIRST 'ABC' for 'XXX' with str_replace
my_char <- str_replace_all(string = my_char,
pattern = 'ABC',
replacement = 'XXX')
print(my_char)R> [1] "XXXDEF-XXXDEF-XXX"Mais uma vez, vale ressaltar que as operações de substituição também funcionam em vetores. Dê uma olhada no próximo exemplo.
# set char object
my_char <- c('ABCDEF','DBCFE','ABC')
# create an example of vector
my_char_vec <- str_c(sample(my_char, 5, replace = T),
sample(my_char, 5, replace = T),
sep = ' - ')
# show it
print(my_char_vec)R> [1] "ABCDEF - ABC" "ABCDEF - ABCDEF" "ABCDEF - ABC"
R> [4] "ABCDEF - DBCFE" "DBCFE - ABCDEF"# substitute all occurrences of 'ABC'
my_char_vec <- str_replace_all(string = my_char_vec,
pattern = 'ABC',
replacement = 'XXX')
# print result
print(my_char_vec)R> [1] "XXXDEF - XXX" "XXXDEF - XXXDEF" "XXXDEF - XXX"
R> [4] "XXXDEF - DBCFE" "DBCFE - XXXDEF"7.2.6 Separando Textos
Em algumas situações, principalmente no processamento de textos, é possível que se esteja interessado em quebrar um texto de acordo com algum separador. Por exemplo, o texto abc ; bcd ; adf apresenta informações demarcadas pelo símbolo ;. Para separar um texto em várias partes, utilizamos a função stringr::str_split/base::strsplit. Essas quebram o texto em diversas partes de acordo com algum caractere escolhido. Observe os exemplos a seguir:
# set char
my_char <- 'ABCXABCXBCD'
# split it based on 'X' and using stringr::str_split
split_char <- str_split(my_char, 'X')
# print result
print(split_char)R> [[1]]
R> [1] "ABC" "ABC" "BCD"A saída dessa função é um objeto do tipo lista. Para acessar os elementos de uma lista, deve-se utilizar o operador [[ ]]. Por exemplo, para acessar o texto bcd da lista split_char, executa-se o seguinte código:
print(split_char[[1]][2])R> [1] "ABC"Para visualizar um exemplo de dividir textos em vetores, veja o próximo código.
# set char
my_char_vec <- c('ABCDEF','DBCFE','ABFC','ACD')
# split it based on 'B' and using stringr::strsplit
split_char <- str_split(my_char_vec, 'B')
# print result
print(split_char)R> [[1]]
R> [1] "A" "CDEF"
R>
R> [[2]]
R> [1] "D" "CFE"
R>
R> [[3]]
R> [1] "A" "FC"
R>
R> [[4]]
R> [1] "ACD"Observe como, novamente, um objeto do tipo list é retornado. Cada elemento é correspondente ao processo de quebra de texto em my_char.
7.2.7 Descobrindo o Número de Caracteres de um Texto
Para descobrir o número de caracteres de um texto, utilizamos a função stringr::str_length/base::nchar. Ela também funciona para vetores atômicos de texto. Veja os exemplos mostrados a seguir:
# set char
my_char <- 'abcdef'
# print number of characters using stringr::str_length
print(str_length(my_char))R> [1] 6E agora um exemplo com vetores.
#set char
my_char <- c('a', 'ab', 'abc')
# print number of characters using stringr::str_length
print(str_length(my_char))R> [1] 1 2 37.2.8 Gerando Combinações de Texto
Um truque útil no R é usar as funções base::outer e base::expand.grid para criar todas as combinações possíveis de elementos em diferentes objetos. Isso é útil quando você quer criar um vetor de texto combinando todos os elementos possíveis de diferentes vetores. Por exemplo, se quisermos criar um vetor com todas as combinações entre c('a' , 'b') e c('A', 'B') como c('a-A', 'a-B', ...), podemos escrever:
# set char vecs
my_vec_1 <- c('a','b')
my_vec_2 <- c('A','B')
# combine in matrix
comb.mat <- outer(my_vec_1,
my_vec_2,
paste,sep = '-')
# print it!
print(comb.mat)R> [,1] [,2]
R> [1,] "a-A" "a-B"
R> [2,] "b-A" "b-B"A saída de outer é um objeto do tipo matriz. Se quisermos mudar comb.mat para um vetor atômico, podemos usar a função as.character:
print(as.character(comb.mat))R> [1] "a-A" "b-A" "a-B" "b-B"Outra maneira de atingir o mesmo objetivo é usar a função expand.grid. Veja o próximo exemplo.
library(tidyverse)
# set vectors
my_vec_1 <- c('John ', 'Claire ', 'Adam ')
my_vec_2 <- c('is fishing.', 'is working.')
# create df with all combinations
my_df <- expand.grid(name = my_vec_1,
verb = my_vec_2)
# print df
print(my_df)R> name verb
R> 1 John is fishing.
R> 2 Claire is fishing.
R> 3 Adam is fishing.
R> 4 John is working.
R> 5 Claire is working.
R> 6 Adam is working.# paste columns together in tibble
my_df <- my_df %>%
mutate(phrase = paste0(name, verb) )
# print result
print(my_df)R> name verb phrase
R> 1 John is fishing. John is fishing.
R> 2 Claire is fishing. Claire is fishing.
R> 3 Adam is fishing. Adam is fishing.
R> 4 John is working. John is working.
R> 5 Claire is working. Claire is working.
R> 6 Adam is working. Adam is working.Aqui, usamos a função expand.grid para criar um dataframe contendo todas as combinações possíveis de my_vec_1 e my_vec_2. Posteriormente, colamos o conteúdo das colunas do dataframe usando str_c.
7.2.9 Codificação de Objetos character
Para o R, um string de texto é apenas uma sequência de bytes. A tradução de bytes para caracteres é realizada de acordo com uma estrutura de codificação. Para a maioria dos casos de uso do R, especialmente em países de língua inglesa, a codificação de caracteres não é um problema pois os textos importados no R já possuem a codificação correta. Ao lidar com dados de texto em diferentes idiomas, tal como Português do Brasil, a codificação de caracteres é algo que você deve entender pois eventualmente precisará lidar com isso.
Vamos explorar um exemplo. Aqui, vamos importar dados de um arquivo de texto com a codificação 'ISO-8859-9' e verificar o resultado.
# read text file
my_f <- adfeR::get_data_file('FileWithLatinChar_Latin1.txt')
my_char <- readr::read_lines(my_f)
# print it
print(my_char)R> [1] "A casa \xe9 bonita e tem muito espa\xe7o"O conteúdo original do arquivo é um texto em português. Como você pode ver, a saída de readr::read_lines mostra todos os caracteres latinos com símbolos estranhos. Isso ocorre pois a codificação foi manualmente trocada para 'ISO-8859-9', enquanto a função read_lines utiliza 'UTF-8' como default. A solução mais fácil e direta é modificar a codificação esperada do arquivo nas entradas de read_lines. Veja a seguir, onde importamos um arquivo com a codificação correta ('Latin1'):
my_char <- readr::read_lines(my_f,
locale = readr::locale(encoding='Latin1'))
# print it
print(my_char)R> [1] "A casa é bonita e tem muito espaço"Os caracteres latinos agora estão corretos pois a codificação em read_lines é a mesma do arquivo, 'Latin1'. Uma boa política neste tópico é sempre verificar a codificação de arquivos de texto importados e combiná-lo em R. A maioria das funções de importação tem uma opção para fazê-lo. Quando possível, sempre dê preferência para 'UTF-8'. Caso necessário, programas de edição de texto, tal como o notepad++, possuem ferramentas para verificar e trocar a codificação de um arquivo.
7.2.10 Outras Funções Úteis
stringr::str_to_lower/base::tolower - Converte um objeto de texto para letras minúsculas.
print(stringr::str_to_lower('ABC'))R> [1] "abc"stringr::str_to_upper/base::toupper - Convertem um texto em letras maiúsculas.
R> [1] "ABC"print(stringr::str_to_upper('abc'))R> [1] "ABC"7.3 Fatores
A classe de fatores (factor) é utilizada para representar grupos ou categorias dentro de uma base de dados no formato tabular. Por exemplo, imagine um banco de informações com os gastos de diferentes pessoas ao longo de um ano. Nessa base de dados existe um item que define o gênero do indivíduo: masculino ou feminino (M ou F). Essa respectiva coluna pode ser importada e representada como texto, porém, no R, a melhor maneira de representá-la é através do objeto fator, uma vez que a mesma representa uma categoria.
A classe de fatores oferece um significado especial para denotar grupos dentro dos dados. Essa organização é integrada aos pacotes e facilita muito a vida do usuário. Por exemplo, caso quiséssemos criar um gráfico para cada grupo dentro da nossa base de dados, poderíamos fazer o mesmo simplesmente indicando a existência de uma variável de fator para a função de criação da figura. Outra possibilidade é determinar se as diferentes médias de uma variável numérica são estatisticamente diferentes para os grupos dos nossos dados. Podemos também estimar um determinado modelo estatístico para cada grupo. Quando os dados de categorias são representados apropriadamente, o uso das funções do R torna-se mais fácil e eficiente.
7.3.1 Criando Fatores
A criação de fatores dá-se através da função factor:
R> [1] M F M M F
R> Levels: F MObserve, no exemplo anterior, que a apresentação de fatores com a função print mostra os seus elementos e também o item chamado Levels. Esse último identifica os possíveis grupos que abrangem o vetor - nesse caso apenas M e F. Se tivéssemos um número maior de grupos, o item Levels aumentaria. Veja a seguir:
R> [1] M F M M F ND
R> Levels: F M NDUm ponto importante na criação de fatores é que os Levels são inferidos através dos dados criados, e isso pode não corresponder à realidade. Por exemplo, observe o seguinte exemplo:
R> [1] Solteiro Solteiro Solteiro
R> Levels: SolteiroNota-se que, por ocasião, os dados mostram apenas uma categoria: Solteiro. Entretanto, sabe-se que outra categoria do tipo Casado é esperada. No caso de utilizarmos o objeto my_status da maneira que foi definida anteriormente, omitiremos a informação de outros gêneros, e isso pode ocasionar problemas no futuro tal como a criação de gráficos incompletos. Nessa situação, o correto é definir os Levels manualmente da seguinte maneira:
my_status <- factor(c('Solteiro', 'Solteiro', 'Solteiro'),
levels = c('Solteiro', 'Casado'))
print(my_status)R> [1] Solteiro Solteiro Solteiro
R> Levels: Solteiro Casado7.3.2 Modificando Fatores
Um ponto importante sobre os objetos do tipo fator é que seus Levels são imutáveis e não atualizam-se com a entrada de novos dados. Em outras palavras, não é possível modificar os valores dos Levels após a criação do objeto. Toda nova informação que não for compatível com os Levels do objeto será transformada em NA (Not available) e uma mensagem de warning irá aparecer na tela. Essa limitação pode parecer estranha a primeira vista porém, na prática, ela evita possíveis erros no código. Veja o exemplo a seguir:
# set factor
my_factor <- factor(c('a', 'b', 'a', 'b'))
# change first element of a factor to 'c'
my_factor[1] <- 'c'R> Warning in `[<-.factor`(`*tmp*`, 1, value = "c"): invalid
R> factor level, NA generated# print result
print(my_factor)R> [1] <NA> b a b
R> Levels: a bNesse caso, a maneira correta de proceder é primeiro transformar o objeto da classe fator para a classe caractere e depois realizar a conversão:
# set factor
my_factor <- factor(c('a', 'b', 'a', 'b'))
# change factor to character
my_char <- as.character(my_factor)
# change first element
my_char[1] <- 'c'
# mutate it back to class factor
my_factor <- factor(my_char)
# show result
print(my_factor)R> [1] c b a b
R> Levels: a b cUtilizando essas etapas temos o resultado desejado no vetor my_factor, com a definição de três Levels: a, b e c.
O universo tidyverse também possui um pacote próprio para manipular fatores, o forcats. Para o problema atual de modificação de fatores, podemos utilizar função forcats::fct_recode. Veja um exemplo a seguir, onde trocamos as siglas dos fatores:
library(forcats)
# set factor
my.fct <- factor(c('A', 'B', 'C', 'A', 'C', 'M', 'N'))
# modify factors
my.fct <- fct_recode(my.fct,
'D' = 'A',
'E' = 'B',
'F' = 'C')
# print result
print(my.fct)R> [1] D E F D F M N
R> Levels: D E F M NObserve como o uso da função forcats::fct_recode é intuitivo. Basta indicar o novo nome dos grupos com o operador de igualdade.
7.3.3 Convertendo Fatores para Outras Classes
Outro ponto importante no uso de fatores é a sua conversão para outras classes, especialmente a numérica. Quando convertemos um objeto de tipo fator para a classe caractere, o resultado é o esperado:
# create factor
my_char <-factor(c('a', 'b', 'c'))
# convert and print
print(as.character(my_char))R> [1] "a" "b" "c"Porém, quando fazemos o mesmo procedimento para a classe numérica, o que o R retorna é longe do esperado:
# set factor
my_values <- factor(5:10)
# convert to numeric (WRONG)
print(as.numeric(my_values))R> [1] 1 2 3 4 5 6Esse resultado pode ser explicado pelo fato de que, internamente, fatores são armazenados como índices, indo de 1 até o número total de Levels. Essa simplificação minimiza o uso da memória do computador. Quando pedimos ao R para transformar esses fatores em números, ele entende que buscamos o número do índice e não do valor. Para contornar, é fácil: basta transformar o objeto fator em caractere e, depois, em numérico, conforme mostrado a seguir:
# converting factors to character and then to numeric
print(as.numeric(as.character(my_values)))R> [1] 5 6 7 8 9 10
Tenha muito cuidado ao transformar fatores em números. Lembre-se
sempre de que o retorno da conversão direta serão os índices dos
levels e não os valores em si. Esse é um bug bem
particular que pode ser difícil de identificar em um código
complexo.
7.3.4 Criando Tabelas de Contingência
Após a criação de um fator, podemos calcular a ocorrência de cada fator com a função table. Essa também é chamada de tabela de contingência. Em um caso simples, com apenas um fator, a função table conta o número de ocorrências de cada categoria, como a seguir:
# create factor
my_factor <- factor(sample(c('Pref', 'Ord'),
size = 20,
replace = TRUE))
# print contingency table
print(table(my_factor))R> my_factor
R> Ord Pref
R> 9 11Um caso mais avançado do uso de table é utilizar mais de um fator para a criação da tabela. Veja o exemplo a seguir:
# set factors
my_factor_1 <- factor(sample(c('Pref', 'Ord'),
size = 20,
replace = TRUE))
my_factor_2 <- factor(sample(paste('Grupo', 1:3),
size = 20,
replace = TRUE))
# print contingency table with two factors
print(table(my_factor_1, my_factor_2))R> my_factor_2
R> my_factor_1 Grupo 1 Grupo 2 Grupo 3
R> Ord 2 4 3
R> Pref 3 4 4A tabela criada anteriormente mostra o número de ocorrências para cada combinação de fator. Essa é uma ferramenta descritiva simples, mas bastante informativa para a análise de grupos de dados.
7.3.5 Outras Funções
levels - Retorna os Levels de um objeto da classe fator.
R> [1] "A" "B" "C"as.factor - Transforma um objeto para a classe fator.
R> [1] a b c c a
R> Levels: a b csplit - Com base em um objeto de fator, cria uma lista com valores de outro objeto. Esse comando é útil para separar dados de grupos diferentes e aplicar alguma função com sapply ou lapply.
my_factor <- factor(c('A','B','C','C','C','B'))
my_x <- 1:length(my_factor)
my_l <- split(x = my_x, f = my_factor)
print(my_l)R> $A
R> [1] 1
R>
R> $B
R> [1] 2 6
R>
R> $C
R> [1] 3 4 57.4 Valores Lógicos
Testes lógicos em dados são centrais no uso do R. Em uma única linha de código podemos testar condições para uma grande quantidade de casos. Esse cálculo é muito utilizado para encontrar casos extremos nos dados (outliers) e também para separar diferentes amostras de acordo com algum critério.
7.4.1 Criando Valores Lógicos
Em uma sequência de 1 até 10, podemos verificar quais são os elementos maiores que 5 com o seguinte código:
# set numerical
my_x <- 1:10
# print a logical test
print(my_x > 5)R> [1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
R> [10] TRUER> [1] 6 7 8 9 10A função which do exemplo anterior retorna os índices onde a condição é verdadeira (TRUE). O uso do which é recomendado quando se quer saber a posição de elementos que satisfazem alguma condição.
Para realizar testes de igualdade, basta utilizar o símbolo de igualdade duas vezes (==).
R> [1] "abc" "bcd" "abc" "bcd" "abc" "bcd" "abc" "bcd" "abc"
R> [10] "bcd"# print logical test
print(my_char == 'abc')R> [1] TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE
R> [10] FALSEPara o teste de inigualdades, utilizamos o símbolo !=:
# print inequality test
print(my_char != 'abc')R> [1] FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE
R> [10] TRUEDestaca-se que também é possível testar condições múltiplas, isto é, a ocorrência simultânea de eventos. Utilizamos o operador & para esse propósito. Por exemplo: se quiséssemos verificar quais são os valores de uma sequência de 1 a 10 que são maiores que 4 e menores que 7, escreveríamos:
my_x <- 1:10
# print logical for values higher than 4 and lower than 7
print((my_x > 4)&(my_x < 7) )R> [1] FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE
R> [10] FALSER> [1] 5 6Para testar condições não simultâneas, isto é, ocorrências de um ou outro evento, utilizamos o operador |. Por exemplo: considerando a sequência anterior, acharíamos os valores maiores que 7 ou menores que 4 escrevendo:
# location of elements higher than 7 or lower than 4
idx <- which( (my_x > 7)|(my_x < 4) )
# print elements from previous condition
print(my_x[idx])R> [1] 1 2 3 8 9 10Observe que, em ambos os casos de uso de testes lógicos, utilizamos parênteses para encapsular as condições lógicas. Poderíamos ter escrito idx <- which( my_x > 7|my_x < 4 ), porém o uso do parênteses deixa o código mais claro ao isolar os testes de condições e sinalizar que o resultado da operação será um vetor lógico. Em alguns casos, porém, o uso do parênteses indica hierarquia na ordem das operações e portanto não pode ser ignorado.
Outro uso interessante de objetos lógicos é o teste para saber se um item ou mais pertence a um vetor ou não. Para isso utilizamos o operador %in%. Por exemplo, imagine que tens os tickers de duas ações, c('ABC', 'DEF') e queres saber se é possível encontrar esses tickers na coluna de outra base de dados. Essa é uma operação semelhante ao uso do teste de igualdade, porém em notação vetorial. Veja um exemplo a seguir:
library(dplyr)
# location of elements higher than 7 or lower than 4
my_tickers <- c('ABC', 'DEF')
# set df
n_obs <- 100
df_temp <- tibble(tickers = sample(c('ABC', 'DEF', 'GHI', 'JKL'),
size = n_obs,
replace = TRUE),
ret = rnorm(n_obs, sd = 0.05) )
# find rows with selected tickers
idx <- df_temp$tickers %in% my_tickers
# print elements from previous condition
glimpse(df_temp[idx, ])R> Rows: 43
R> Columns: 2
R> $ tickers <chr> "ABC", "ABC", "ABC", "DEF", "DEF", "ABC", …
R> $ ret <dbl> 0.042864781, 0.017056405, 0.011198439, 0.0…O dataframe mostrado na tela possui dados apenas para ações em my_tickers.
7.5 Datas e Tempo
A representação e manipulação de datas é um importante aspecto das pesquisas em Finanças e Economia. Manipular datas e horários de forma correta, levando em conta mudanças decorridas de horário de verão, feriados locais, em diferentes zonas de tempo, não é uma tarefa fácil! Felizmente, o R fornece um grande suporte para qualquer tipo de operação com datas e tempo.
Nesta seção estudaremos as funções e classes nativas que representam e manipulam o tempo em R. Aqui, daremos prioridade as funções do pacote lubridate (Spinu, Grolemund, and Wickham 2022). Existem, no entanto, muitos pacotes que podem ajudar o usuário a processar objetos do tipo data e tempo de forma mais avançada. Caso alguma operação com data e tempo não for encontrada aqui, sugiro o estudo dos pacotes chron (James and Hornik 2022), timeDate (Wuertz, Setz, and Chalabi 2022) e bizdays (Freitas 2022).
Antes de começarmos, vale relembrar que toda data no R segue o formato ISO 8601 (YYYY-MM-DD), onde YYYY é o ano em quatro números, MM é o mês e DD é o dia. Por exemplo, uma data em ISO 8601 é 2022-11-23. Deves familiarizar-se com esse formato pois toda importação de dados com formato de datas diferente desta notação exigirá conversão. Felizmente, essa operação é bastante simples de executar com o lubridate.
7.5.1 Criando Datas Simples
No R, existem diversas classes que podem representar datas. A escolha entre uma classe de datas e outra baseia-se na necessidade da pesquisa. Em muitas situações não é necessário saber o horário, enquanto que em outras isso é extremamente pertinente pois os dados são coletados ao longo de um dia.
A classe mais básica de datas é Date. Essa indica dia, mês e ano, apenas. No lubridate, criamos datas verificando o formato da data de entrada e as funções ymd (year-month-date), dmy (day-month-year) e mdy (month-day-year). Veja a seguir:
R> [1] "2021-06-24"R> [1] "2021-06-24"R> [1] "2021-06-24"Note que as funções retornam exatamente o mesmo objeto. A diferença no uso é somente pela forma que a data de entrada está estruturada com a posição do dia, mês e ano.
Um benefício no uso das funções do pacote lubridate é que as mesmas são inteligentes ao lidar com formatos diferentes. Observe no caso anterior que definimos os elementos das datas com o uso do traço (-) como separador e valores numéricos. Outros formatos também são automaticamente reconhecidos:
R> [1] "2021-06-24"R> [1] "2021-06-24"R> [1] "2021-06-24"R> [1] "2021-06-24"Isso é bastante útil pois o formato de datas no Brasil é dia/mês/ano (DD/MM/YYYY). Ao usar dmy para uma data brasileira, a conversão é correta:
R> [1] "2021-06-24"Já no pacote base, a função correspondente é as.Date. O formato da data, porém, deve ser explicitamente definido com argumento format, conforme mostrado a seguir:
# set Date from dd/mm/yyyy with the definition of format
my_date <- as.Date('24/06/2021', format = '%d/%m/%Y')
# print result
print(my_date)R> [1] "2021-06-24"Os símbolos utilizados na entrada format, tal como %d e %Y, são indicadores de formato, os quais definem a forma em que a data a ser convertida está estruturada. Nesse caso, os símbolos %Y, %m e %d definem ano, mês e dia, respectivamente. Existem diversos outros símbolos que podem ser utilizados para processar datas em formatos específicos. Um panorama das principais codificações é apresentado a seguir:
| Código | Valor | Exemplo |
|---|---|---|
| %d | dia do mês (decimal) | 0 |
| %m | mês (decimal) | 12 |
| %b | mês (abreviado) | Abr |
| %B | mês (nome completo) | Abril |
| %y | ano (2 dígitos) | 16 |
| %Y | ano (4 dígitos) | 2021 |
Os símbolos anteriores permitem a criação de datas a partir de variados formatos. Observe como a utilização das funções do lubridate, em relação a base, são mais simples e fáceis de utilizar, justificando a nossa escolha.
7.5.2 Criando Sequências de Datas
Um aspecto interessante no uso de objetos do tipo Date é que eles interagem com operações de adição de valores numéricos e com testes lógicos de comparação de datas. Por exemplo: caso quiséssemos adicionar um dia à data my_date criada anteriormente, bastaria somar o valor 1 ao objeto:
# create date
my_date <- ymd('2021-06-24')
# find next day
my_date_2 <- my_date + 1
# print result
print(my_date_2)R> [1] "2021-06-25"A propriedade também funciona com vetores, o que deixa a criação de sequências de datas muito fácil. Nesse caso, o próprio R encarrega-se de verificar o número de dias em cada mês.
# create a sequence of Dates
my_date_vec <- my_date + 0:15
# print it
print(my_date_vec)R> [1] "2021-06-24" "2021-06-25" "2021-06-26" "2021-06-27"
R> [5] "2021-06-28" "2021-06-29" "2021-06-30" "2021-07-01"
R> [9] "2021-07-02" "2021-07-03" "2021-07-04" "2021-07-05"
R> [13] "2021-07-06" "2021-07-07" "2021-07-08" "2021-07-09"Uma maneira mais customizável de criar sequências de datas é utilizar a função seq. Com ela, é possível definir intervalos diferentes de tempo e até mesmo o tamanho do vetor de saída. Caso quiséssemos uma sequência de datas de dois em dois dias, poderíamos utilizar o seguinte código:
# set first and last Date
my_date_1 <- ymd('2021-03-07')
my_date_2 <- ymd('2021-03-20')
# set sequence
my_date_date <- seq(from = my_date_1,
to = my_date_2,
by = '2 days')
# print result
print(my_date_date)R> [1] "2021-03-07" "2021-03-09" "2021-03-11" "2021-03-13"
R> [5] "2021-03-15" "2021-03-17" "2021-03-19"Caso quiséssemos de duas em duas semanas, escreveríamos:
# set first and last Date
my_date_1 <- ymd('2021-03-07')
my_date_2 <- ymd('2021-04-20')
# set sequence
my_date_date <- seq(from = my_date_1,
to = my_date_2,
by = '2 weeks')
# print result
print(my_date_date)R> [1] "2021-03-07" "2021-03-21" "2021-04-04" "2021-04-18"Outra forma de utilizar seq é definir o tamanho desejado do objeto de saída. Por exemplo, caso quiséssemos um vetor de datas com 10 elementos, usaríamos:
# set first and last Date
my_date_1 <- ymd('2021-03-07')
my_date_2 <- ymd('2021-10-20')
# set sequence
my_date_vec <- seq(from = my_date_1,
to = my_date_2,
length.out = 10)
# print result
print(my_date_vec)R> [1] "2021-03-07" "2021-04-01" "2021-04-26" "2021-05-21"
R> [5] "2021-06-15" "2021-07-11" "2021-08-05" "2021-08-30"
R> [9] "2021-09-24" "2021-10-20"O intervalo entre as datas em my_date_vec é definido automaticamente pelo R.
7.5.3 Operações com Datas
É possível descobrir a diferença de dias entre datas simplesmente diminuindo uma data da outra:
# set dates
my_date_1 <- ymd('2015-06-24')
my_date_2 <- ymd('2016-06-24')
# calculate difference
diff_date <- my_date_2 - my_date_1
# print result
print(diff_date)R> Time difference of 366 daysA saída da operação de subtração é um objeto da classe diffdate, o qual possui a classe de lista como sua estrutura básica. Destaca-se que a notação de acesso aos elementos da classe diffdate é a mesma utilizada para listas. O valor numérico do número de dias está contido no primeiro elemento de diff_date:
# print difference of days as numerical value
print(diff_date[[1]])R> [1] 366Podemos testar se uma data é maior do que outra com o uso das operações de comparação:
# set date and vector
my_date_1 <- ymd('2016-06-20')
my_date_vec <- ymd('2016-06-20') + seq(-5,5)
# test which elements of my_date_vec are older than my_date_1
my_test <- (my_date_vec > my_date_1)
# print result
print(my_test)R> [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE
R> [10] TRUE TRUEA operação anterior é bastante útil quando se está buscando filtrar um determinado período de tempo nos dados. Nesse caso, basta buscar nas datas o período específico em que estamos interessados e utilizar o objeto lógico da comparação para selecionar os elementos. Veja o exemplo a seguir:
library(dplyr)
library(lubridate)
# set first and last dates
first_date <- ymd('2016-06-01')
last_date <- ymd('2016-06-15')
# create `dataframe` and glimpse it
my_temp_df <- tibble(date_vec = ymd('2016-05-25') + seq(0,30),
prices=seq(1,10,
length.out = length(date_vec)))
glimpse(my_temp_df)R> Rows: 31
R> Columns: 2
R> $ date_vec <date> 2016-05-25, 2016-05-26, 2016-05-27, 2016…
R> $ prices <dbl> 1.0, 1.3, 1.6, 1.9, 2.2, 2.5, 2.8, 3.1, 3…# find dates that are between the first and last date
my_idx <- (my_temp_df$date_vec >= first_date) &
(my_temp_df$date_vec <= last_date)
# use index to filter `dataframe`
my_temp_df_filtered <- my_temp_df %>%
filter(my_idx) %>%
glimpse()R> Rows: 15
R> Columns: 2
R> $ date_vec <date> 2016-06-01, 2016-06-02, 2016-06-03, 2016…
R> $ prices <dbl> 3.1, 3.4, 3.7, 4.0, 4.3, 4.6, 4.9, 5.2, 5…Nesse caso, o vetor final de preços da coluna prices contém apenas informações para o período entre first_date e last_date.
7.5.4 Lidando com Data e Tempo
O uso da classe Date é suficiente quando se está lidando apenas com datas. Em casos em que é necessário levar em consideração o horário, temos que utilizar um objeto do tipo datetime.
No pacote base, uma das classes utilizadas para esse fim é a POSIXlt, a qual armazena o conteúdo de uma data na forma de uma lista. Outra classe que também é possível utilizar é a POSIXct, que armazena as datas como segundos contados a partir de 1970-01-01. Devido ao seu formato de armazenamento, a classe POSIXct ocupa menos memória do computador. Junto ao lubridate, a classe utilizada para representar data-tempo é POSIXct e portanto daremos prioridade a essa. Vale destacar que todos os exemplos apresentados aqui também podem ser replicados para objetos do tipo POSIXlt.
O formato tempo/data também segue a norma ISO 8601, sendo representado como ano-mês-dia horas:minutos:segundos zonadetempo (YYYY-MM-DD HH:mm:SS TMZ). Veja o exemplo a seguir:
# creating a POSIXct object
my_timedate <- as.POSIXct('2021-01-01 16:00:00')
# print result
print(my_timedate)R> [1] "2021-01-01 16:00:00 -03"O pacote lubridate também oferece funções inteligentes para a criação de objetos do tipo data-tempo. Essas seguem a mesma linha de raciocínio que as funções de criar datas. Veja a seguir:
library(lubridate)
# creating a POSIXlt object
my_timedate <- ymd_hms('2021-01-01 16:00:00')
# print it
print(my_timedate)R> [1] "2021-01-01 16:00:00 UTC"Destaca-se que essa classe adiciona automaticamente o fuso horário. Caso seja necessário representar um fuso diferente, é possível fazê-lo com o argumento tz:
# creating a POSIXlt object with custom timezone
my_timedate_tz <- ymd_hms('2021-01-01 16:00:00',
tz = 'GMT')
# print it
print(my_timedate_tz)R> [1] "2021-01-01 16:00:00 GMT"É importante ressaltar que, para o caso de objetos do tipo POSIXlt e POSIXct, as operações de soma e diminuição referem-se a segundos e não dias, como no caso do objeto da classe Date.
# Adding values (seconds) to a POSIXlt object and printing it
print(my_timedate_tz + 30)R> [1] "2021-01-01 16:00:30 GMT"Assim como para a classe Date, existem símbolos específicos para lidar com componentes de um objeto do tipo data/tempo. Isso permite a formatação customizada de datas. A seguir, apresentamos um quadro com os principais símbolos e os seus respectivos significados.
| Código | Valor | Exemplo |
|---|---|---|
| %H | Hora (decimal, 24 horas) | 23 |
| %I | Hora (decimal, 12 horas) | 11 |
| %M | Minuto (decimal, 0-59) | 12 |
| %p | Indicador AM/PM | AM |
| %S | Segundos (decimal, 0-59) | 50 |
A seguir veremos como utilizar essa tabela para customizar datas.
7.5.5 Personalizando o Formato de Datas
A notação básica para representar datas e data/tempo no R pode não ser a ideal em algumas situações. No Brasil, por exemplo, indicar datas no formato YYYY-MM-DD pode gerar bastante confusão em um relatório formal. É recomendado, portanto, modificar a representação das datas para o formato esperado, isto é, DD/MM/YYYY.
Para formatar uma data, utilizamos a função format. Seu uso baseia-se nos símbolos de data e de horário apresentados anteriormente. A partir desses, pode-se criar qualquer customização. Veja o exemplo a seguir, onde apresenta-se a modificação de um vetor de datas para o formato brasileiro:
# create vector of dates
my_dates <- seq(from = ymd('2021-01-01'),
to = ymd('2021-01-15'),
by = '1 day')
# change format
my_dates_br <- format(my_dates, '%d/%m/%Y')
# print result
print(my_dates_br)R> [1] "01/01/2021" "02/01/2021" "03/01/2021" "04/01/2021"
R> [5] "05/01/2021" "06/01/2021" "07/01/2021" "08/01/2021"
R> [9] "09/01/2021" "10/01/2021" "11/01/2021" "12/01/2021"
R> [13] "13/01/2021" "14/01/2021" "15/01/2021"O mesmo procedimento pode ser realizado para objetos do tipo data/tempo (POSIXct):
# create vector of date-time
my_datetime <- ymd_hms('2021-01-01 12:00:00') + seq(0,560,60)
# change to Brazilian format
my_dates_br <- format(my_datetime, '%d/%m/%Y %H:%M:%S')
# print result
print(my_dates_br)R> [1] "01/01/2021 12:00:00" "01/01/2021 12:01:00"
R> [3] "01/01/2021 12:02:00" "01/01/2021 12:03:00"
R> [5] "01/01/2021 12:04:00" "01/01/2021 12:05:00"
R> [7] "01/01/2021 12:06:00" "01/01/2021 12:07:00"
R> [9] "01/01/2021 12:08:00" "01/01/2021 12:09:00"Pode-se também customizar para formatos bem específicos. Veja a seguir:
# set custom format
my_dates_custom <- format(my_dates,
'Year=%Y | Month=%m | Day=%d')
# print result
print(my_dates_custom)R> [1] "Year=2021 | Month=01 | Day=01"
R> [2] "Year=2021 | Month=01 | Day=02"
R> [3] "Year=2021 | Month=01 | Day=03"
R> [4] "Year=2021 | Month=01 | Day=04"
R> [5] "Year=2021 | Month=01 | Day=05"
R> [6] "Year=2021 | Month=01 | Day=06"
R> [7] "Year=2021 | Month=01 | Day=07"
R> [8] "Year=2021 | Month=01 | Day=08"
R> [9] "Year=2021 | Month=01 | Day=09"
R> [10] "Year=2021 | Month=01 | Day=10"
R> [11] "Year=2021 | Month=01 | Day=11"
R> [12] "Year=2021 | Month=01 | Day=12"
R> [13] "Year=2021 | Month=01 | Day=13"
R> [14] "Year=2021 | Month=01 | Day=14"
R> [15] "Year=2021 | Month=01 | Day=15"7.5.6 Extraindo Elementos de uma Data
Para extrair elementos de datas tal como o ano, mês, dia, hora, minuto e segundo, uma alternativa é utilizar função format. Observe o próximo exemplo, onde recuperamos apenas as horas de um objeto POSIXct:
library(lubridate)
# create vector of date-time
my_datetime <- seq(from = ymd_hms('2021-01-01 12:00:00'),
to = ymd_hms('2021-01-01 18:00:00'),
by = '1 hour')
# get hours from POSIXlt
my_hours <- as.numeric(format(my_datetime, '%H'))
# print result
print(my_hours)R> [1] 12 13 14 15 16 17 18Da mesma forma, poderíamos utilizar os símbolos %M e %S para recuperar facilmente minutos e segundos de um vetor de objetos POSIXct.
# create vector of date-time
my_datetime <- seq(from = ymd_hms('2021-01-01 12:00:00'),
to = ymd_hms('2021-01-01 18:00:00'),
by = '15 min')
# get minutes from POSIXlt
my_minutes <- as.numeric(format(my_datetime, '%M'))
# print result
print(my_minutes)R> [1] 0 15 30 45 0 15 30 45 0 15 30 45 0 15 30 45 0 15
R> [19] 30 45 0 15 30 45 0Outra forma é utilizar as funções do lubridate, tal como hour e minute:
R> [1] 12 12 12 12 13 13 13 13 14 14 14 14 15 15 15 15 16 16
R> [19] 16 16 17 17 17 17 18R> [1] 0 15 30 45 0 15 30 45 0 15 30 45 0 15 30 45 0 15
R> [19] 30 45 0 15 30 45 0Outras funções também estão disponíveis para os demais elementos de um objeto data-hora.
7.5.7 Conhecendo o Horário e a Data Atual
O R inclui várias funções que permitem o usuário utilizar no seu código o horário e data atual do sistema. Isso é bastante útil quando se está criando registros e é importante que a data e horário de execução do código seja conhecida futuramente.
Para conhecer o dia atual, basta utilizarmos a função base::Sys.Date ou lubridate::today:
R> [1] "2022-11-23"R> [1] "2022-11-23"Para descobrir a data e horário, utilizamos a função base::Sys.time ou lubridate::now:
R> [1] "2022-11-23 10:53:23 -03"R> [1] "2022-11-23 10:53:23 -03"Com base nessas, podemos escrever:
library(stringr)
# example of log message
my_str <- str_c('This code was executed in ', now())
# print it
print(my_str)R> [1] "This code was executed in 2022-11-23 10:53:23"7.5.8 Outras Funções Úteis
weekdays - Retorna o dia da semana de uma ou várias datas.
# set date vector
my_dates <- seq(from = ymd('2021-01-01'),
to = ymd('2021-01-5'),
by = '1 day')
# find corresponding weekdays
my_weekdays <- weekdays(my_dates)
# print it
print(my_weekdays)R> [1] "Friday" "Saturday" "Sunday" "Monday" "Tuesday"months - Retorna o mês de uma ou várias datas.
# create date vector
my_dates <- seq(from = ymd('2021-01-01'),
to = ymd('2021-12-31'),
by = '1 month')
# find months
my_months <- months(my_dates)
# print result
print(my_months)R> [1] "January" "February" "March" "April"
R> [5] "May" "June" "July" "August"
R> [9] "September" "October" "November" "December"quarters - Retorna a localização de uma ou mais datas dentro dos quartis do ano.
R> [1] "Q1" "Q1" "Q1" "Q2" "Q2" "Q2" "Q3" "Q3" "Q3" "Q4" "Q4"
R> [12] "Q4"OlsonNames - Retorna um vetor com as zonas de tempo disponíveis no R. No total, são mais de 500 itens. Aqui, apresentamos apenas os primeiros cinco elementos.
# get possible timezones
possible_tz <- OlsonNames()
# print it
print(possible_tz[1:5])R> [1] "Africa/Abidjan" "Africa/Accra"
R> [3] "Africa/Addis_Ababa" "Africa/Algiers"
R> [5] "Africa/Asmara"Sys.timezone - Retorna a zona de tempo do sistema.
# get current timezone
print(Sys.timezone())R> [1] "America/Sao_Paulo"cut - Retorna um fator a partir da categorização de uma classe de data e tempo.
# set example date vector
my_dates <- seq(from = ymd('2021-01-01'),
to = ymd('2021-03-01'),
by = '5 days')
# group vector based on monthly breaks
my_month_cut <- cut(x = my_dates,
breaks = 'month')
# print result
print(my_month_cut)R> [1] 2021-01-01 2021-01-01 2021-01-01 2021-01-01 2021-01-01
R> [6] 2021-01-01 2021-01-01 2021-02-01 2021-02-01 2021-02-01
R> [11] 2021-02-01 2021-02-01
R> Levels: 2021-01-01 2021-02-01# set example datetime vector
my_datetime <- as.POSIXlt('2021-01-01 12:00:00') + seq(0,250,15)
# set groups for each 30 seconds
my_cut <- cut(x = my_datetime, breaks = '30 secs')
# print result
print(my_cut)R> [1] 2021-01-01 12:00:00 2021-01-01 12:00:00
R> [3] 2021-01-01 12:00:30 2021-01-01 12:00:30
R> [5] 2021-01-01 12:01:00 2021-01-01 12:01:00
R> [7] 2021-01-01 12:01:30 2021-01-01 12:01:30
R> [9] 2021-01-01 12:02:00 2021-01-01 12:02:00
R> [11] 2021-01-01 12:02:30 2021-01-01 12:02:30
R> [13] 2021-01-01 12:03:00 2021-01-01 12:03:00
R> [15] 2021-01-01 12:03:30 2021-01-01 12:03:30
R> [17] 2021-01-01 12:04:00
R> 9 Levels: 2021-01-01 12:00:00 ... 2021-01-01 12:04:00
7.6 Dados Omissos - NA (Not available)
Uma das principais inovações do R em relação a outras linguagens de programação é a representação de dados omissos através de objetos da classe NA (Not Available). A falta de dados pode ter inúmeros motivos, tal como a falha na coleta de informações ou simplesmente a não existência dos mesmos. Esses casos são tratados por meio da remoção ou da substituição dos dados omissos antes realizar uma análise mais profunda. A identificação desses casos, portanto, é de extrema importância.
7.6.1 Definindo Valores NA
Para definirmos os casos omissos nos dados, basta utilizar o símbolo NA:
R> [1] 1 2 NA 4 5Vale destacar que a operação de qualquer valor NA com outro sempre resultará em NA.
# example of NA interacting with other objects
print(my_x + 1)R> [1] 2 3 NA 5 6Isso exige cuidado quando se está utilizando alguma função com cálculo recursivo, tal como cumsum e cumprod. Nesses casos, todo valor consecutivo ao NA será transformado em NA. Veja os exemplos a seguir com as duas funções:
# set vector with NA
my_x <- c(1:5, NA, 5:10)
# print cumsum (NA after sixth element)
print(cumsum(my_x))R> [1] 1 3 6 10 15 NA NA NA NA NA NA NAR> [1] 1 2 6 24 120 NA NA NA NA NA NA NA
Toda vez que utilizar as funções cumsum e
cumprod, certifique-se de que não existe algum valor
NA no vetor de entrada. Lembre-se de que todo
NA é contagiante e o cálculo recursivo irá resultar em um
vetor repleto de dados faltantes.
7.6.2 Encontrando e Substituindo Valores NA
Para encontrar os valores NA em um vetor, basta utilizar a função is.na:
# set vector with NA
my_x <- c(1:2, NA, 4:10)
# find location of NA
idx_na <- is.na(my_x)
print(idx_na)R> [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
R> [10] FALSEPara substituí-los, use indexação com a saída de is.na:
# set vector
my_x <- c(1, NA, 3:4, NA)
# replace NA for 2
my_x[is.na(my_x)] <- 2
# print result
print(my_x)R> [1] 1 2 3 4 2Outra maneira de limpar o objeto é utilizar a função na.omit, que retorna o mesmo objeto mas sem os valores NA. Note, porém, que o tamanho do vetor irá mudar e o objeto será da classe omit, o que indica que o vetor resultante não inclui os NA e apresenta, também, a posição dos elementos NA encontrados.
R> [1] "a" "b" "c" NA "e" "f" "g" "h"R> [1] "a" "b" "c" "e" "f" "g" "h"
R> attr(,"na.action")
R> [1] 4
R> attr(,"class")
R> [1] "omit"Apesar de o tipo de objeto ter sido trocado, devido ao uso de na.omit, as propriedades básicas do vetor inicial se mantêm. Por exemplo: o uso de nchar no objeto resultante é possível.
R> [1] 1 1 1 1 1 1 1Para outros objetos, porém, recomenda-se cautela quando no uso da função na.omit.
7.6.3 Outras Funções Úteis
complete.cases - Retorna um vetor lógico que indica se as linhas do objeto possuem apenas valores não omissos. Essa função é usada exclusivamente para dataframes e matrizes.
# create matrix
my_mat <- matrix(1:15, nrow = 5)
# set an NA value
my_mat[2,2] <- NA
# print index with rows without NA
print(complete.cases(my_mat))R> [1] TRUE FALSE TRUE TRUE TRUE7.7 Exercícios
Q.1
Considere os seguintes os vetores x e y:
set.seed(7)
x <- sample (1:3, size = 5, replace = T)
y <- sample (1:3, size = 5, replace = T)Qual é a soma dos elementos de um novo vetor resultante da multiplicação entre os elementos de x e y?
Resposta:
set.seed(7)
x <- sample (1:3, size = 5, replace = T)
y <- sample (1:3, size = 5, replace = T)
# solution
my_sol <- sum(x*y)
Q.2
Caso realizássemos uma soma cumulativa de uma sequência entre 1 e 100, em qual elemento esta soma iria passar de 50?
Resposta:
my_sum <- cumsum(1:100)
# solution
my_sol <- (which(my_sum > 50)[1])
Q.3
Utilizando o R, crie uma sequência em objeto chamado seq_1 entre -15 e 10, onde o intervalo entre valores é sempre igual a 2. Qual o valor da soma dos elementos de seq_1?
Resposta:
# solution
seq_1 <- seq(from = -15, to = 10, by = 2)
# solution
my_sol <- sum(seq_1)
Q.4
Defina outro objeto chamado seq_2 contendo uma sequência de tamanho 1000, com valores entre 0 e 100. Qual é o desvio padrão (função sd) dessa sequência?
Resposta:
seq_2 <- seq(from = 0,
to = 100,
length.out = 1000)
# solution
my_sol <- sd(seq_2)
Q.5
Calcule a soma entre vetores seq_1 e seq_2 (veja exercício anterior). Esta operação funcionou apesar do tamanho diferente dos vetores? Explique sua resposta. Caso funcionar, qual o maior valor do vetor resultante?
Resposta:
Sim, funcionou, mas com um aviso de warning: _ “o comprimento do objeto mais longo não é um múltiplo do comprimento do objeto mais curto” _. A explicação é que sempre que R encontra operações com vetor de tamanhos diferentes, ele usa a regra de reciclagem, onde o vetor mais curto é repetido quantas vezes forem necessárias para coincidir com o tamanho do vetor mais longo. No livro, veja seção sobre vetores numéricos para maiores detalhes.
seq_1 <- seq(from = -10, to = 10, by = 2)
seq_2 <- seq(from = 0,
to = 100,
length.out = 1000)
# solution
my_sol <- max(seq_1+seq_2)
Q.6
Vamos supor que, em certa data, você comprou 100 ações de uma empresa, a price_purchase reais por ação. Depois de algum tempo, você vendeu 30 ações por 18 reais cada e as 70 ações restantes foram vendidas por 22 reais em um dia posterior. Usando um script em R, estruture este problema financeiro criando objetos numéricos. Qual é o lucro bruto desta transação no mercado de ações?
Resposta:
total_shares <- 100
price_purchase <- 15
total_purchase_value <- total_shares*price_purchase
qtd_sell_1 <- 30
price_sell_1 <- 18
total_sell_1 <- qtd_sell_1*18
qtd_sell_2 <- total_shares-qtd_sell_1
price_sell_2 <- 22
total_sell_2 <- qtd_sell_2*price_sell_2
total_sell_value <- total_sell_1 + total_sell_2
# solution
my_sol <- total_sell_value - total_purchase_value
Q.7
Crie um vetor x de acordo com a fórmula a seguir, onde . Qual é o valor da soma dos elementos de x?
Resposta:
i <- 1:100
x <- ( (-1)^(i+1) )/(2*i - 1)
# solution
my_sol <- sum(x)
Q.8
Crie um vetor de acordo com a fórmula a seguir onde e . Qual é o valor da soma dos elementos de ? Dica: veja o funcionamento da função dplyr::lag.
Resposta:
x <- 1:50
y <- 50:1
# solution using `base`
z <- (y - c(NA, x[1:(length(x)-1)]))/c(NA, NA, y[1:(length(y)-2)])
# solution with tidyverse (much prettier huh!)
z <- (y - lag(x, n = 1))/lag(y, n = 2)
# solution (be aware of the NA values)
my_sol <- sum(z, na.rm = TRUE)
Q.9
Usando uma semente de valor 22 em set.seed(), crie um objeto chamado x com valores aleatórios da distribuição Normal com média igual a 10 e desvio padrão igual a 10. Usando função cut, crie outro objeto que defina dois grupos com base em valores de x maiores que 15 e menores que 15. Qual a quantidade de observações no primeiro grupo?
Resposta:
my_seed <- sample(1:50, 1)
set.seed(my_seed)
x <- rnorm(n = 1000, mean = 10, sd = 10)
my_group <- cut(x,
breaks = c(-Inf, 15, Inf))
# solution
my_sol <- table(my_group)[1]
Q.10
Crie o seguinte objeto com o código a seguir:
set.seed(15)
my_char <- paste(sample(letters, 5000, replace = T),
collapse = '')Qual a quantidade de vezes que a letra 'x' é encontrada no objeto de texto resultante?
Resposta:
set.seed(15)
my_char <- paste(sample(letters, 5000, replace = T),
collapse = '')
# solution
my_sol <- str_count(my_char, 'x')
Q.11
Baseado no objeto my_char criado anteriormente, caso dividíssemos o mesmo em diversos pedaços menores utilizando a letra "b", qual é o número de caracteres no maior pedaço encontrado?
Resposta:
set.seed(15)
my_char <- paste(sample(letters, 5000, replace = T),
collapse = '')
my_split <- str_split(my_char, pattern = 'b')[[1]]
# find number of characters in each
n_chars <- sapply(my_split, nchar)
# solution
my_sol <- n_chars[which.max(n_chars)]
Q.12
No endereço https://www.gutenberg.org/files/1342/1342-0.txt é possível acessar um arquivo .txt contendo o texto integral do livro Pride and Prejudice de Jane Austen. Utilize funções download.file e readr::read_lines para importar o livro inteiro como um vetor de caracteres chamado my_book no R. Quantas linhas o objeto resultante possui?
Resposta:
my_link <- 'https://www.gutenberg.org/ebooks/2264.txt.utf-8'
my_book <- readr::read_lines(my_link)
# solution
my_sol <- length(my_book)
Q.13
Junte o vetor de caracteres em my_book para um único valor (texto) em outro objeto chamado full_text usando função paste0(my_book, collapse = '\n'). Utilizando este último e pacote stringr, quantas vezes a palavra 'King' é repetida na totalidade do texto?
Resposta:
my_link <- 'https://www.gutenberg.org/ebooks/2264.txt.utf-8'
my_book <- readr::read_lines(my_link)
# solution
full_text <- paste0(my_book, collapse = '\n')
my_sol <- stringr::str_count(full_text, stringr::fixed('King'))
Q.14
Para o objeto full_text criado anteriormente, utilize função stringr::str_split para quebrar o texto inteiro em função de espaços em branco. Com base nesse, crie uma tabela de frequência. Qual a palavra mais utilizada no texto? Dica: Remova todos os casos de caracteres vazios ('').
Resposta:
my_link <- 'https://www.gutenberg.org/ebooks/2264.txt.utf-8'
my_book <- readr::read_lines(my_link)
# solution
full_text <- paste0(my_book, collapse = '\n')
my_split <- stringr::str_split(full_text,
pattern = stringr::fixed(' '))[[1]]
# remove empty
my_split <- my_split[my_split != '']
my_tab <- sort(table(my_split), decreasing = TRUE)
# solution
my_sol <- names(my_tab[1])
Q.15
Assumindo que uma pessoa nascida em 2000-05-12 irás viver for 100 anos, qual é o número de dias de aniversário que cairão em um final de semana (sábado ou domingo)? Dica: use operador %in% para checar uma condição múltipla nos dados.
Resposta:
b_day <- as.Date('2000-05-12')
n_years <- 100
b_day_vec <- seq(b_day, b_day + n_years*365, by = '1 year')
w_days <- weekdays(b_day_vec)
n_weekend <- sum(
stringr::str_to_lower(w_days) %in% c('sábado', "domingo")
)
# solution
my_sol <- n_weekend
Q.16
Qual data e horário é localizado 10^{4} segundos após 2021-02-02 11:50:02?
Resposta:
time_1 <- as.POSIXct('2021-02-02 11:50:02')
my_sec <- 10000
my_sol <- time_1 + my_sec