Question
O grupo LatinoMetrics produz e distribui um conteúdo muito interessante de visualização de dados econômicos para a América Latina. Observando o material do Instagram, visualize as seis últimas imagens disponibilizadas na página principal. Observando as figuras como um todo, destaque os elementos comuns na criação das imagens. Isto, é, destaque os elementos visuais que foram repetidos entre uma figura e outra.
Solution
Em um acesso do dia 27/09/2022, observa-se as seis últimas publicações da página do LatinoMetrics do Instagram.

Seis últimas publicações do LatinoMetrics em 27/09/2022
Nota-se os seguintes elementos repetidos entre uma figura e outra:
Todos gráficos possuem a mesma cor de fundo, e logo do LatinoMetrics em algum lugar.
A paleta de cores dos interior do gráfico tende a ser relacionada ao tema. Veja, por exemplo, que o primeiro gráfico – “A Mexican Abuelita has One of the Hottest coking Channels” – usa o vermelho e azul para distinguir canais individuais e corporativos do Youtube.
A origem dos dados é sempre definida no caption, texto abaixo e esquerda do gráfico.
Todas legendas sempre ficam abaixo do título ou no interior do gráfico.
Sempre que possível, observa-se o uso expressivo de símbolos e logos. Por exemplo, o logo de empresas é utilizado ostensivamente ao longo de diferentes figuras.
Question
No Reddit é possível encontrar o grupo r/dataisugly, o qual contém inúmeros posts sobre visualizações de dados realizadas da forma errada. Na data de 27/09/2022 foi publicado a seguinte mensagem no fórum:
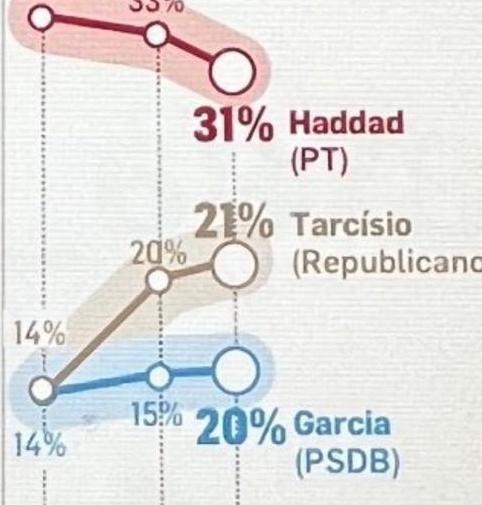
Publicação do reddit/dataisuglu em 27/09/2022
Analise o gráfico e, sem buscar a resposta no fórum, indique qual o problema com o gráfico.
Solution
O problema do gráfico é a escala errada para o eixo vertical. Note que o valor de 20% é compartilhado pelo candidatos Garcia e Tarcísio, porém em localizações muito diferentes! É impossível de dizer se foi erro do programador ou alguma intenção política. Porém, o visual do gráfico indica, para os mesmos pontos de dados, mais peso visual para um candidato do que para o outro.
Question
Em 22/09/2022, o grupo LatinoMetrics publicou uma visualização de dados a respeito da impressão de confiança da população brasileira em relação as diferens mídias jornalísticas. O conteúdo pode ser acessado no Instagram, e é disponilizado abaixo:
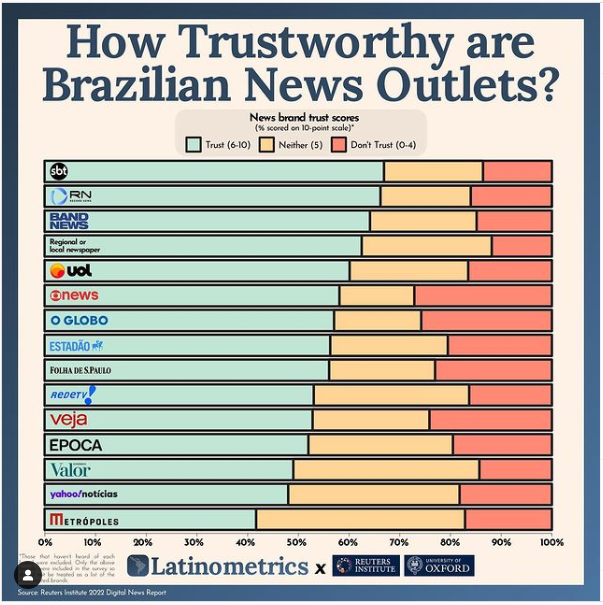
Postagem do LatinoMetrics em 22/09/2022
Observando a figura, destaque os elementos textuais e gráficos utilizados pelo autor.
Solution
Os elementos textuais são:
- título com fonte maior, e caption com origem dos dados. Nota-se também que eixos x e y não possuem texto algum.
Os elementos gráficos:
Uso de barras horizontais com a percentagem de respostas dos entrevistados.
Ordenamento das barras, de forma que a mídia com maior percentagem de confiança, o SBT, fique acima das demais.
uso de logos das mídias jornalísticas no lado esquerdo do gráfico.
uso de cores para direcionar a interpretação do gráfico. A cor vermelha indica a “não confiança” na emissora, enquanto a azul indica confiança.
Question
Statspanda é outro grupo especializado em produção de conteúdo relacionado a visualização de dados, porém com assuntos muito mais abrangentes que o LatinoMetrics. Em 17/09/2022, o grupo publicou a seguinte figura no Instagram:
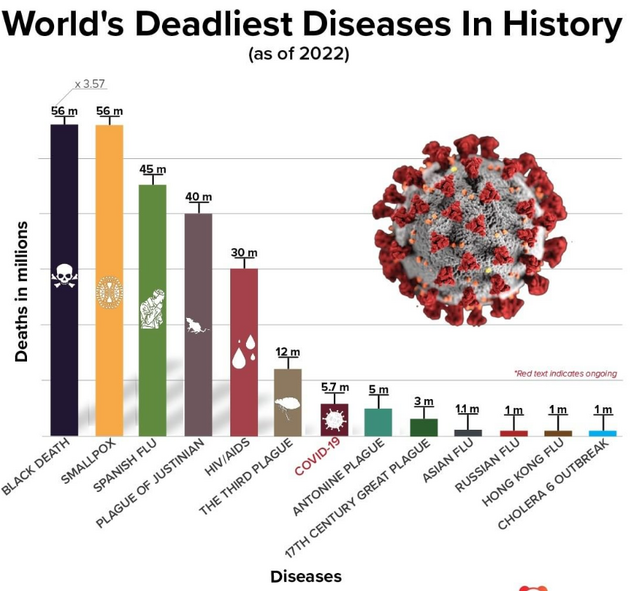
Postagem do Statspanda em 19/09/2022
Neste caso, quais foram os elementos gráficos utilizados pelo autor e como os mesmos se associam a mensagem da figura.
Solution
Os elementos textuais são:
título e subtítulo com a mensagem do gráfico;
textos nos eixos verticais e horizontais;
o número de mortes acima de cada barra do gráfico, sendo usando uma escala padronizada de milhões (1m);
Os elementos gráficos são:
uso de barras verticais para indicar a mortalidade das diferentes doenças;
uso de logos para as doenças de maior mortalidade;
uso de cores sugestivas, com cor preta para a doença mais mortífera;
Realçe do caso da COVID, com cor vermelha.
Question
No Reddit/dataisbeautiful é possível encontrar a visualização da receita de todos os filmes da franchise Star Wars.
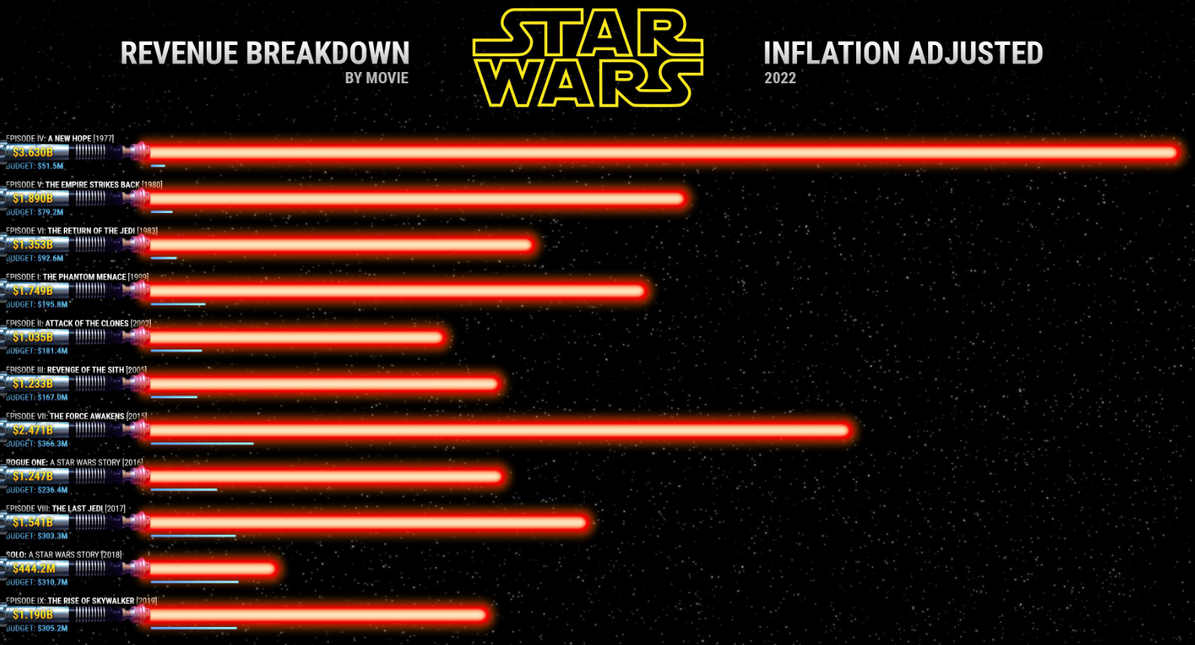
Postagem do Reddit/dataisbeautiful
Apesar de ser esteticamante interessante, o mesmo poderia ser melhorado. Com base no que aprendeu neste capítulo do livro, analise o gráfico e faça recomendações para sua melhoria buscando sempre maior claridade e simplicidade.
Solution
Assumindo que a mensagem do gráfico é o faturamente ano a ano de todos os filmes relacionados a franchise, as mudanças que certamente melhorariam o gráfico são:
- modificar o gráfico para um com o tempo no eixo horizontal, o qual é mais intuitivo ao mostrar o tempo evoluindo para a direita;
- usar barras verticais para cada filme, adicionando um texto com o “budget” de cada filme no topo de cada barra;
- remover as “espadas de laser” e outros elementos visuais desnecessários, as quais não tem finalidade alguma na interpretação do gráfico e não adicionam informação relevante;
- usar cores para ressaltar os filmes com maiores faturamentos, possivelmente com uma paleta de cores de intensidade;
Question
Em um novo script do R, crie um vetor de valores aleatórios da distribuição Normal com o comando rnorm(N), onde N é igual a 100. Agora, crie um gráfico de pontos onde o eixo y é representado pela série anterior, e o eixo x é simplesmente a contagem dos valores (1..100). Para este gráfico, utilize o template básico do ggplot2, isto é, não precisas modificar nenhum elemento textual do gráfico, por enquanto.
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N
)
p <- ggplot(df, aes(x = x, y = y)) +
geom_point()
p
plot of chunk solution
Question
Para o gráfico anterior, adicione os seguintes elementos textuais e gráficos:
- título, subtítulo;
- caption com a data e tempo de compilação do gráfico;
- textos nos eixos x e y;
- aplique o tema
theme_light
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N
)
p <- ggplot(df, aes(x = x, y = y)) +
geom_point() +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = stringr::str_glue("Compilado em {Sys.time()}"),
x = "texto X",
y = "texto Y") +
theme_light()
p
plot of chunk solution
Question
Para o mesmo gráfico anterior, adicione uma nova coluna chamada type no dataframe, a qual pode tomar o valor “A” ou “B”. Para isto, podes usar o comando sample(c("A", "B"), size = N, replace = TRUE). Note que o valor de N foi definido anteriormente.
Com base no novo dataframe, crie um gráfico de linhas com cores diferentes para cada valor em type.
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N,
type = sample(c("A", "B"), size = N, replace = TRUE)
)
p <- ggplot(df, aes(x = x, y = y, color = type)) +
geom_point() +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = "CAPTION",
x = "texto X",
y = "texto Y") +
theme_light()
p
plot of chunk solution
Question
Para o mesmo gráfico anterior, adicione uma camada de linhas no gráfico.
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N,
type = sample(c("A", "B"), size = N, replace = TRUE)
)
p <- ggplot(df, aes(x = x, y = y, color = type)) +
geom_point() +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = "CAPTION",
x = "texto X",
y = "texto Y") +
theme_light() +
geom_line()
p
plot of chunk solution
Question
Agora, use o gráfico anterior, mas modifique o formato dos pontos, definindo que o argumento shape será mapeado de acordo com coluna type. Também aumente o tamanho de todos os pontos do gráfico para 3.
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N,
type = sample(c("A", "B"), size = N, replace = TRUE)
)
p <- ggplot(df, aes(x = x, y = y,
color = type,
shape = type)) +
geom_point(size = 3) +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = "CAPTION",
x = "texto X",
y = "texto Y") +
theme_light() +
geom_line()
p
plot of chunk solution
Question
Agora, modifique o código para que o tamanho dos pontos seja relativo a coluna x do dataframe de entrada. Isto é, o efeito desejado é que os pontos aumentem de tamanho ao longo do eixo horizontal.
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N,
type = sample(c("A", "B"), size = N, replace = TRUE)
)
p <- ggplot(df, aes(x = x, y = y,
color = type,
shape = type)) +
geom_point(aes(size = x)) +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = "CAPTION",
x = "texto X",
y = "texto Y") +
geom_line()
p
plot of chunk solution
Question
Neste exercício, remova a camada de pontos utilizada no gráfico e adicione o texto disponível na coluna type (A ou B) no mesmo local onde os pontos se situavam.
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N,
type = sample(c("A", "B"), size = N, replace = TRUE)
)
p <- ggplot(df, aes(x = x, y = y,
color = type,
label = type)) +
#geom_point(aes(size = x)) +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = "CAPTION",
x = "texto X",
y = "texto Y") +
geom_line() +
geom_text()
p
plot of chunk solution
Question
Para o gráfico anterior, use as funções do pacote colorspace para implementar a paleta de cores “Harmonic” do canal color (dados qualitativos).
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N,
type = sample(c("A", "B"), size = N, replace = TRUE)
)
p <- ggplot(df, aes(x = x, y = y,
color = type,
label = type)) +
#geom_point(aes(size = x)) +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = "CAPTION",
x = "texto X",
y = "texto Y") +
geom_line() +
geom_text() +
colorspace::scale_colour_discrete_qualitative("Harmonic")
p
plot of chunk solution
Question
Exporte a figura anterior com as seguintes informações:
- arquivo de exportação chamado “fig-eoc-vdr.png” e localizado na pasta padrão “Documentos” (atalho com
~); - use um tamanho 10 X 10 em centímetros
Verifique se o arquivo foi criado corretamente na pasta desejada.
Solution
require(ggplot2)
N <- 100
vec <- rnorm(N)
df <- dplyr::tibble(
y = vec,
x = 1:N,
type = sample(c("A", "B"), size = N, replace = TRUE)
)
p <- ggplot(df, aes(x = x, y = y,
color = type,
label = type)) +
#geom_point(aes(size = x)) +
labs(title = "TÍTULO",
subtitle = "SUBTÍTULO",
caption = "CAPTION",
x = "texto X",
y = "texto Y") +
geom_line() +
geom_text() +
colorspace::scale_colour_discrete_qualitative("Harmonic")
f_png <- "~/fig-eoc-vdr.png"
ggsave(filename = f_png, plot = p,
height = 10, width = 10, units = "cm")
fs::file_exists(f_png)## ~/fig-eoc-vdr.png
## TRUEQuestion
Com base na função yfR::yf_collection_get, baixe os dados de preços de ações para a composição atual do índice Ibovespa, com início a cinco anos atrás e término como sendo a data atual. Com base nos dados importados, siga os seguintes passos:
- filtre os dados para manter apenas as 5 ações com maior rentabilidade acumulado na período, e as 5 com menor.
- construa uma figura com os retornos acumulados das 10 ações selecionadas anteriormente, onde o eixo horizontal representa as datas.
- Implemente as seguintes modificações no gráfico:
- Adicione título, subtítulo e caption e também o texto dos eixo horizontal e vertical;
- modifique a escala do eixo horizontal para percentagens com comando
scale_y_continuous(labels = scales::percent); - use o tema
theme_light;
- exporte a figura resultante para um arquivo de tamanha tamanho 10 cm (height) X 15 cm (width) chamado “fig-ibov-10-ações.png”, e localizado na pasta padrão “Documentos” (atalho com
~);
Solution
library(ggplot2)
df_ibov <- yfR::yf_collection_get("IBOV",
first_date = Sys.Date() - 5*365)
# passo 01
df_tab <- df_ibov |>
dplyr::group_by(ticker ) |>
dplyr::summarize(final_ret = dplyr::last(cumret_adjusted_prices)) |>
dplyr::arrange(final_ret)
n_selected <- 5
selected <- dplyr::bind_rows(
head(df_tab, n_selected),
tail(df_tab, n_selected)
)
df_ibov <- df_ibov |>
dplyr::filter(ticker %in% selected$ticker)
p <- ggplot(df_ibov, aes(x = ref_date, y = cumret_adjusted_prices,
color = ticker)) +
# passo 02
geom_line() +
# passo 03
labs(title = "Retornos acumulados para 10 ações do Ibovespa",
subtitle = stringr::str_glue("Dados entre {min(df_ibov$ref_date)} e {max(df_ibov$ref_date)}"),
caption = stringr::str_glue("Compilado em {Sys.time()}"),
x = "Dias",
y = "Retorno Acumulado") +
scale_y_continuous(labels = scales::percent) +
theme_light()
p
# passo 04
f_png <- "~/fig-ibov-10-ações.png"
ggsave(filename = f_png, plot = p,
height = 10, width = 15, units = "cm")
fs::file_exists(f_png)Question
Utilizando o pacote yfR, baixe os dados dos preços da Grendene, ticker = GRND3.SA, desde 2015 até o data atual. Com base nos dados importados, crie um histograma dos retornos diários dos preços ajustados da ação (coluna ret_adjusted_prices).
Solution
library(ggplot2)
ticker <- "GRND3.SA"
df_yf <- yfR::yf_get(ticker,
first_date = "2015-01-01",
last_date = Sys.Date())## ## ── Running yfR for 1 stocks | 2015-01-01 --> 2022-11-23 (2883 days) ──## ## ℹ Downloading data for benchmark ticker ^GSPC## ℹ (1/1) Fetching data for GRND3.SA## ✔ - found cache file (2015-01-02 --> 2022-11-22)## ✔ - got 1961 valid rows (2015-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Time for some tea?## ℹ Binding price data## ## ── Diagnostics ───────────────────────────────────## ✔ Returned dataframe with 1961 rows -- Good job msperlin!## ℹ Using 1.0 MB at /tmp/Rtmp7Djxn9/yf_cache for 7 cache files## ℹ Out of 1 requested tickers, you got 1 (100%)p <- ggplot(df_yf, aes(x = ret_adjusted_prices)) +
geom_histogram()
p## `stat_bin()` using `bins = 30`. Pick better value
## with `binwidth`.
plot of chunk solution
Question
Utilizando o pacote yfR e argumento freq_data = 'monthly' em yf_get, baixe os dados dos preços mensais da Petrobras, ticker = PETR3.SA, de 2015 até o dia atual. Com base nos dados importados, crie um histograma dos retornos mensais da ação, adicionando os seguintes itens ao gráfico:
- título e subtítulo;
- texto no eixo x e y;
- caption;
- tema
theme_light
Solution
library(ggplot2)
library(stringr)
ticker <- "PETR3.SA"
df_yf <- yfR::yf_get(ticker, freq_data = 'monthly',
first_date = "2015-01-01",
last_date = Sys.Date())## ## ── Running yfR for 1 stocks | 2015-01-01 --> 2022-11-23 (2883 days) ──## ## ℹ Downloading data for benchmark ticker ^GSPC## ℹ (1/1) Fetching data for PETR3.SA## ✔ - found cache file (2015-01-02 --> 2022-11-22)## ✔ - got 1961 valid rows (2015-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Got it!## ℹ Binding price data## ## ── Diagnostics ───────────────────────────────────## ✔ Returned dataframe with 95 rows -- Youre doing good!## ℹ Using 1.0 MB at /tmp/Rtmp7Djxn9/yf_cache for 7 cache files## ℹ Out of 1 requested tickers, you got 1 (100%)p <- ggplot(df_yf, aes(x = ret_adjusted_prices)) +
geom_histogram() +
labs(
title = str_glue("Histograma de Retornos Mensais da {ticker}"),
subtitle = str_glue("Dados entre {min(df_yf$ref_date)} e {max(df_yf$ref_date)}"),
caption = "Dados do Yahoo Finance",
x = "Retorno Mensal",
y = "Frequência"
) +
theme_light()
p## `stat_bin()` using `bins = 30`. Pick better value
## with `binwidth`.
plot of chunk solution
Question
Pacote microdatasus, criado por Raphael Saldanha (rfsaldanha), importa e limpa dados do Sistema de Saúde Único (SUS). No pacote do livro é possível encontrar dados de mortalidade importados pelo microdatasus e filtrados para manter apenas algumas colunas da base completa. O arquivo é chamado Exercises-sus-mortality-data.csv e pode ser importado com a função vdr::data_import.
Com base nos dados da coluna age, crie um gráfico de densidade para a distribuição de idades de falecimento, incluindo os seguintes itens no gráfico:
- título;
- texto no eixo x e y;
- caption;
- tema
theme_light
Solution
library(ggplot2)
df_sus <- vdr::data_import("Exercises-sus-mortality-data.csv")
p <- ggplot(df_sus , aes(x = age)) +
geom_density() +
labs(
title = stringr::str_glue("Densidade de Mortalidade para o RS"),
subtitle = stringr::str_glue("Dados para os anos de 2019 e 2020"),
caption = "Dados do SUS (importado com microdatasus)",
x = "Idade de Morte",
y = "Densidade"
) +
theme_light()
p
plot of chunk solution
Question
Para os mesmos dados de mortalidade retirados do SUS, crie um gráfico QQ com a distribuição de idades de falecimento (coluna age).
Solution
library(ggplot2)
df_sus <- vdr::data_import("Exercises-sus-mortality-data.csv")
p <- ggplot(df_sus , aes(sample = age)) +
geom_qq() +
geom_qq_line()
p
plot of chunk solution
Question
Considerando novamente os dados de mortalidade do SUS, crie um gráfico de densidade de distribuição, porém separe as linhas do gráfico de acordo com o gênero (Masculino/Feminino). Isto é, queremos uma linha de densidade para o sexo masculino, e outra para o feminino. Dica: remova os casos de SEXO = NA (Not Available) antes de criar o gráfico.
Solution
library(ggplot2)
library(stringr)
df_sus <- vdr::data_import("Exercises-sus-mortality-data.csv")
p <- ggplot(df_sus, aes(x = age, color = SEXO)) +
geom_density() +
labs(
title = str_glue("Densidade de Mortalidade para o RS"),
subtitle = str_glue("Dados para os anos de 2019 e 2020"),
caption = "Dados do SUS (importado com microdatasus)",
x = "Idade de Morte",
y = "Densidade"
) +
theme_light()
p
plot of chunk solution
Question
Repita o exercício anterior, porém use facetas para mostrar as diferentes densidades de mortalidade entre os gêneros masculino e feminino. Dentro da função facet_wrap, use argumento nrow = 2 para empilhar os painéis verticalmente.
Solution
library(ggplot2)
library(stringr)
df_sus <- vdr::data_import("Exercises-sus-mortality-data.csv")
p <- ggplot(df_sus , aes(x = age)) +
geom_density() +
labs(
title = str_glue("Densidade de Mortalidade para o RS"),
subtitle = str_glue("Dados para os anos de 2019 e 2020"),
caption = "Dados do SUS (importado com microdatasus)",
x = "Idade de Morte",
y = "Densidade"
) +
theme_light() +
facet_wrap(~SEXO, nrow = 2)
p
plot of chunk solution
Question
Considerando novamente os dados do SUS, use o comando facet_grid para mostrar as densidades de idade de falecimento quando separando os dados por gênero (coluna SEXO) e escolaridade (coluna ESC). DICA: remova os casos de NA (Not Available) encontrados em ambas colunas, SEXO e ESC.
Solution
library(ggplot2)
library(stringr)
df_sus <- vdr::data_import("Exercises-sus-mortality-data.csv")
p <- ggplot(df_sus , aes(x = age)) +
geom_density() +
labs(
title = str_glue("Densidade de Mortalidade para o RS"),
subtitle = str_glue("Dados para os anos de 2019 e 2020"),
caption = "Dados do SUS (importado com microdatasus)",
x = "Idade de Morte",
y = "Densidade"
) +
theme_light() +
facet_grid(ESC~SEXO)
p
plot of chunk solution
Question
Crie um gráfico de diagrama (boxplot), onde o eixo horizontal é a escolaridade (coluna ESC) e o eixo vertical representa a distribuição dos dados de idade de falecimento, coluna (age).
Solution
library(ggplot2)
library(stringr)
df_sus <- vdr::data_import("Exercises-sus-mortality-data.csv")
p <- ggplot(df_sus , aes(x = ESC, y = age)) +
geom_boxplot() +
labs(
title = str_glue("Distribuição de mortalidade para diferentes escolariedades"),
subtitle = str_glue("Dados para os anos de 2019 e 2020"),
caption = "Dados do SUS (importado com microdatasus)",
x = "Escolaridade",
y = "Idade de falecimento"
) +
theme_light()
p
plot of chunk solution
Question
Utilizando função geobr::read_country, baixe os dados do território do Brasil e mostre a área em um novo gráfico.
Solution
br <- geobr::read_country()## Using year 2010p <- ggplot() +
geom_sf(data = br)
p
plot of chunk solution
Question
Utilizando função geobr::read_indigenous_land, baixe os dados do território indígena no Brasil e adicione esta camada ao gráfico do Brasil criado anteriormente, com as fronteiras da área indígena representadas na cor vermelha.
Solution
df_sf <- geobr::read_indigenous_land()## Using year 201907br <- geobr::read_country()## Using year 2010p <- ggplot() +
geom_sf(data = br) +
geom_sf(data = df_sf, color = 'red')
p
plot of chunk solution
Question
Utilizando função geobr::read_state(), baixe os dados de todos os estados do Brasil e, em um mapa do país, mostre os limites de cada estado na cor azul.
Solution
df_states <- geobr::read_state(code_state = "all")## Using year 2010##
|
| | 0%br <- geobr::read_country()## Using year 2010p <- ggplot() +
geom_sf(data = br) +
geom_sf(data = df_states,
color = 'blue')
p
plot of chunk solution
Question
Utilizando função geobr::read_state(), baixe os dados do estado do Rio Grande do Sul e, com os dados disponíveis no arquivo “Chapter07-latlong-cities-brazil.csv” do pacote vdr:
- mostre as cidades gaúchas como pontos azuis no mapa, ajustando o tamanho e transparência dos pontos para melhor visualização do mapa;
- mostre a capital, Porto alegre, como um ponto vermelho com tamanho e intensidade maior.
- adicione o texto “PORTO ALEGRE” em preto, acima do ponto de localização da capital.
- adicione título e caption para o gráfico
Solution
df_rs <- geobr::read_state(code_state = "RS")## Using year 2010f_cities <- "Chapter07-latlong-cities-brazil.csv"
df_cities_rs <- vdr::data_import(f_cities) |>
dplyr::filter(codigo_uf == 43) # 43 is state of RS
poa <- df_cities_rs |>
dplyr::filter(capital == TRUE)
p <- ggplot() +
geom_sf(data = df_rs) +
# etapa 01
geom_point(data = df_cities_rs,
aes(y = latitude, x = longitude),
color = 'blue',
size = 1,
alpha = 0.5) +
# etapa 02
geom_point(data = poa,
aes(y = latitude, x = longitude),
color = 'red',
size = 2,
alpha = 1) +
# etapa 03
geom_text(data = poa,
aes(y = latitude, x = longitude,
label = "PORTO ALEGRE"),
color = 'black',
size = 3,
alpha = 1,
nudge_y = 0.25) +
# etapa 04
labs(title = "Cidades do Estado do Rio Grande do Sul",
caption = "Dados do IBGE e pacote vdr")
p
plot of chunk solution
Question
O código abaixo irá criar um gráfico simples com os preços da ação da empresa Engie (EGIE.SA).
library(ggplot2)
df_yf <- yfR::yf_get("EGIE3.SA",
first_date = "2018-01-01")## ## ── Running yfR for 1 stocks | 2018-01-01 --> 2022-11-23 (1787 days) ──## ## ℹ Downloading data for benchmark ticker ^GSPC## ℹ (1/1) Fetching data for EGIE3.SA## ✔ - found cache file (2018-01-02 --> 2022-11-22)## ✔ - got 1212 valid rows (2018-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Good job msperlin!## ℹ Binding price data## ## ── Diagnostics ───────────────────────────────────## ✔ Returned dataframe with 1212 rows -- Looking good!## ℹ Using 1.0 MB at /tmp/Rtmp7Djxn9/yf_cache for 7 cache files## ℹ Out of 1 requested tickers, you got 1 (100%)p <- ggplot(
df_yf,
aes(x = ref_date, y = price_adjusted)
) + geom_line()Após a execução do código acima, use as ferramentas de programação do R para testar os seguintes temas da figura:
ggplot2::theme_light()ggplot2::theme_bw()ggplot2::theme_grey()ggplot2::theme_minimal()
e lembre de adicionar a informação do tema no título da figura.
Solution
plot_fct <- function(theme_str, p) {
this_theme <- eval(parse(text = theme_str))
p <- p +
this_theme() +
labs(title = stringr::str_glue("{theme_str}"))
return(p)
}
my_themes <- c(
"ggplot2::theme_light",
"ggplot2::theme_bw",
"ggplot2::theme_grey",
"ggplot2::theme_minimal"
)
l_p <- purrr::map(my_themes, plot_fct, p = p)
cowplot::plot_grid(plotlist = l_p)
plot of chunk solution
Question
Considere o gráfico template gerado pelo código a seguir:
library(ggplot2)
p <- ggplot(
yfR::yf_get("USIM5.SA", first_date = "2018-01-01"),
aes(x = ref_date, y = price_adjusted)
) +
geom_line() +
labs(subtitle = "SUBTITLE",
caption = "CAPTION")## ## ── Running yfR for 1 stocks | 2018-01-01 --> 2022-11-23 (1787 days) ──## ## ℹ Downloading data for benchmark ticker ^GSPC## ℹ (1/1) Fetching data for USIM5.SA## ✔ - found cache file (2018-01-02 --> 2022-11-22)## ✔ - got 1212 valid rows (2018-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- You got it msperlin!## ℹ Binding price data## ## ── Diagnostics ───────────────────────────────────## ✔ Returned dataframe with 1212 rows -- Nice!## ℹ Using 1.0 MB at /tmp/Rtmp7Djxn9/yf_cache for 7 cache files## ℹ Out of 1 requested tickers, you got 1 (100%)Pacote hrbrthemes oferece uma grande variedade de temas adicionais a serem utilizados em um gráfico do ggplot2. Todas funções de tema possum um padrão bem distinto, onde o nome da função inicia com o texto theme_. Baseado nesta informação e também no uso da função ls, podemos descobrir o nome de todas as funções de tema do hrbrthemes com o código abaixo:
library(hrbrthemes)
all_fcts <- ls("package:hrbrthemes")
idx <- all_fcts |>
stringr::str_which("theme_")
theme_fcts <- all_fcts[idx]Com base no código anterior:
- use as ferramentas de programação do R para, de forma automática, aplicar todos os temas anteriores para o gráfico gerado acima.
- agrege todos os gráfico em um único arquivo com função
cowplot::plot_grid - salve a figura resultante como
hrbrthemes-demo.png, pasta documentos (atalho com~). Defina o tamanho da figura como height = 20cm e width = 30cm. DICA: Caso a figura gravada sair com fundo transparente, abra-a em um navegador da web, tal como o Chrome ou firefox.
Solution
library(hrbrthemes)
library(ggplot2)
plot_fct <- function(theme_str, p) {
this_theme <- eval(parse(text = theme_str))
p <- p +
this_theme() +
labs(title = stringr::str_glue("{theme_str}"))
return(p)
}
all_fcts <- ls("package:hrbrthemes")
idx <- all_fcts |>
stringr::str_which("theme_")
theme_fcts <- all_fcts[idx]
# fina all theme fcts
my_themes <- theme_fcts
l_p <- purrr::map(my_themes, plot_fct, p = p)
p_grid <- cowplot::plot_grid(plotlist = l_p)
p_grid
plot of chunk solution
ggsave("~/hrbrthemes-demo.png", p_grid, height = 20, width = 30, units = "cm")Question
Considere o gráfico criado de barras criado com o código abaixo:
library(ggplot2)
tickers <- c("PETR3.SA", "ITSA3.SA",
"GRND3.SA", "GGBR3.SA",
"EGIE3.SA", "USIM5.SA")
df_yf <- yfR::yf_get(tickers,
"2020-01-01") ## ## ── Running yfR for 6 stocks | 2020-01-01 --> 2022-11-23 (1057 days) ──## ## ℹ Downloading data for benchmark ticker ^GSPC## ℹ (1/6) Fetching data for EGIE3.SA## ✔ - found cache file (2018-01-02 --> 2022-11-22)## ✔ - got 718 valid rows (2020-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Looking good!## ℹ (2/6) Fetching data for GGBR3.SA## ✔ - found cache file (2020-01-02 --> 2022-11-22)## ✔ - got 718 valid rows (2020-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Looking good!## ℹ (3/6) Fetching data for GRND3.SA## ✔ - found cache file (2015-01-02 --> 2022-11-22)## ✔ - got 718 valid rows (2020-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Looking good!## ℹ (4/6) Fetching data for ITSA3.SA## ✔ - found cache file (2020-01-02 --> 2022-11-22)## ✔ - got 718 valid rows (2020-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Mais contente que cusco de cozinheira!## ℹ (5/6) Fetching data for PETR3.SA## ✔ - found cache file (2015-01-02 --> 2022-11-22)## ✔ - got 718 valid rows (2020-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- You got it msperlin!## ℹ (6/6) Fetching data for USIM5.SA## ✔ - found cache file (2018-01-02 --> 2022-11-22)## ✔ - got 718 valid rows (2020-01-02 --> 2022-11-22)## ✔ - got 96% of valid prices -- Mas bah tche, que coisa linda!## ℹ Binding price data## ## ── Diagnostics ───────────────────────────────────## ✔ Returned dataframe with 4308 rows -- Good job msperlin!## ℹ Using 1.0 MB at /tmp/Rtmp7Djxn9/yf_cache for 7 cache files## ℹ Out of 6 requested tickers, you got 6 (100%)df_tab <- df_yf |>
dplyr::group_by(ticker) |>
dplyr::summarise(
total_ret = dplyr::last(cumret_adjusted_prices) - 1
) |>
dplyr::arrange(total_ret)
p <- ggplot(df_tab, aes(x = reorder(ticker, total_ret),
y = total_ret,
fill = total_ret)) +
geom_col(color = "white") +
theme_minimal() +
coord_flip() +
labs(title = stringr::str_glue(
"Performance de {length(tickers)} Ações Selecionadas"
),
y = "Retorno Total",
x = "Ticker")Com base no código anterior, use as ferramentas de programação do R para, de forma automática, aplicar todas as possíveis combinações entre os temas:
- ggplot2::theme_light
- hrbrthemes::theme_modern_rc
- ggtech::theme_airbnb_fancy()
e as paletas do colorspace
- Red-Green
- Green-Brown
- Tropic
Adicionalmente:
- agrege todos os gráfico em um único arquivo com função
cowplot::plot_grid - salve a figura resultante como
themes-and-palettes-demo.png, pasta documentos (atalho com~). Defina o tamanho da figura como height = 30cm e width = 60cm. DICA: Caso a figura gravada sair com fundo transparente, abra-a em um navegador da web, tal como o Chrome ou firefox.
Solution
library(ggplot2)
plot_fct <- function(theme_str, palette, p) {
this_theme <- eval(parse(text = theme_str))
p <- p +
this_theme() +
labs(
subtitle = stringr::str_glue(
"{theme_str} | {palette}"
),
title = "Demonstração") +
colorspace::scale_fill_binned_diverging(palette)
return(p)
}
theme_fcts <- c(
"ggplot2::theme_light",
"hrbrthemes::theme_ipsum_es",
"ggtech::theme_airbnb_fancy"
)
palettes <- c(
"Red-Green",
"Green-Brown",
"Tropic"
)
df_grid <- tidyr::expand_grid(
theme_fcts,
palettes
)
l_args <- list(
theme_str = df_grid$theme_fcts,
palette = df_grid$palettes
)
l_p <- purrr::pmap(.l = l_args, .f = plot_fct, p = p)
p_grid <- cowplot::plot_grid(plotlist = l_p)
p_grid
plot of chunk solution
ggsave("~/themes-and-palettes-demo.png", p_grid, height = 40, width = 60, units = "cm")