Benchmarking a SSD drive in reading and writing files with R
I recently bought a new computer for home and it came with two drives, one HDD and other SSD. The later is used for the OS and the former stores all of my personal files. From all computers I had, both home and work, this is definitely the fastest. While some of the merits are due to the newer CPUS and RAM, the SSD drive can make all the difference in file operations.
My research usually deals with large files from financial markets. Being efficient in reading those files is key to my productivity. Given that, I was very curious in understanding how much I would benefit in speed when reading/writing files in my SSD drive instead of the HDD. For that, I wrote a simple function that will time a particular operation. The function will take as input the number of rows in the data (1..Inf), the type of function used to save the file (rds, csv, fst) and the type of drive (HDD or SSD). See next.
bench.fct <- function(N = 2500000, type.file = 'rds', type.hd = 'HDD') {
# Function for timing read and write operations
#
# INPUT: N - Number of rows in dataframe to be read and write
# type.file - format of output file (rds, csv, fst)
# type.hd - where to save (hdd or ssd)
#
# OUTPUT: A dataframe with results
require(tidyverse)
require(fst)
my.df <- data_frame(x = runif(N),
char.vec = sample(letters, size = N,
replace = TRUE))
path.file <- switch(type.hd,
'SSD' = '~',
'HDD' = '/mnt/HDD/')
my.file <- file.path(path.file,
switch (type.file,
'rds-base' = 'temp_rds.rds',
'rds-readr' = 'temp_rds.rds',
'fst' = 'temp_fst.fst',
'csv-readr' = 'temp_csv.csv',
'csv-base' = 'temp_csv.csv'))
if (type.file == 'rds-base') {
time.write <- system.time(saveRDS(my.df, my.file, compress = FALSE))
time.read <- system.time(readRDS(my.file))
} else if (type.file == 'rds-readr') {
time.write <- system.time(write_rds(x = my.df, path = my.file, compress = 'none'))
time.read <- system.time(read_rds(path = my.file ))
} else if (type.file == 'fst') {
time.write <- system.time(write.fst(x = my.df, path = my.file))
time.read <- system.time(read_fst(my.file))
} else if (type.file == 'csv-readr') {
time.write <- system.time(write_csv(x = my.df, path = my.file))
time.read <- system.time(read_csv(file = my.file, col_types = cols(x = col_double(),
char.vec = col_character())))
} else if (type.file == 'csv-base') {
time.write <- system.time(write.csv(x = my.df, file = my.file))
time.read <- system.time(read.csv(file = my.file))
}
# clean up
file.remove(my.file)
# save output
df.out <- data_frame(type.file = type.file,
type.hd = type.hd,
N = N,
type.time = c('write',
'read'),
times = c(time.write[3],
time.read[3]))
return(df.out)
}Now that we have my function, its time to use it for all combinations between number of rows, the formats of the file and type of drive:
library(purrr)
df.grid <- expand.grid(N = seq(1, 500000, by = 50000),
type.file = c('rds-readr', 'rds-base', 'fst', 'csv-readr', 'csv-base'),
type.hd = c('HDD', 'SSD'), stringsAsFactors = F)
l.out <- pmap(list(N = df.grid$N,
type.file = df.grid$type.file,
type.hd = df.grid$type.hd), .f = bench.fct)## Warning: `data_frame()` is deprecated as of tibble 1.1.0.
## Please use `tibble()` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.df.res <- do.call(what = bind_rows, args = l.out)Lets check the result in a nice plot:
library(ggplot2)
p <- ggplot(df.res, aes(x = N, y = times, linetype = type.hd)) +
geom_line() + facet_grid(type.file ~ type.time)
print(p)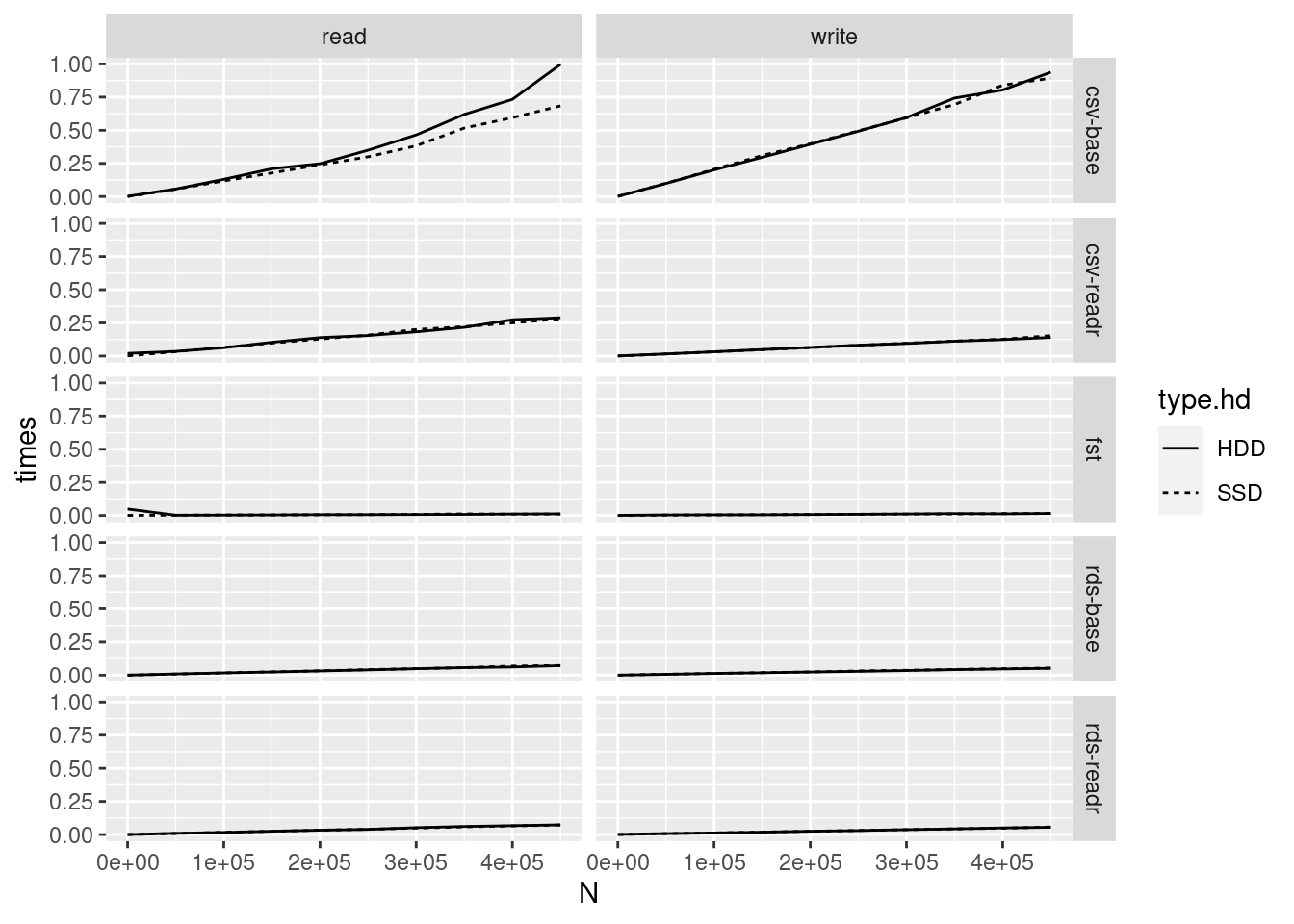
As you can see, the csv-base format is messing with the y axis. Let’s remove it for better visualization:
library(ggplot2)
p <- ggplot(filter(df.res, !(type.file %in% c('csv-base'))),
aes(x = N, y = times, linetype = type.hd)) +
geom_line() + facet_grid(type.file ~ type.time)
print(p)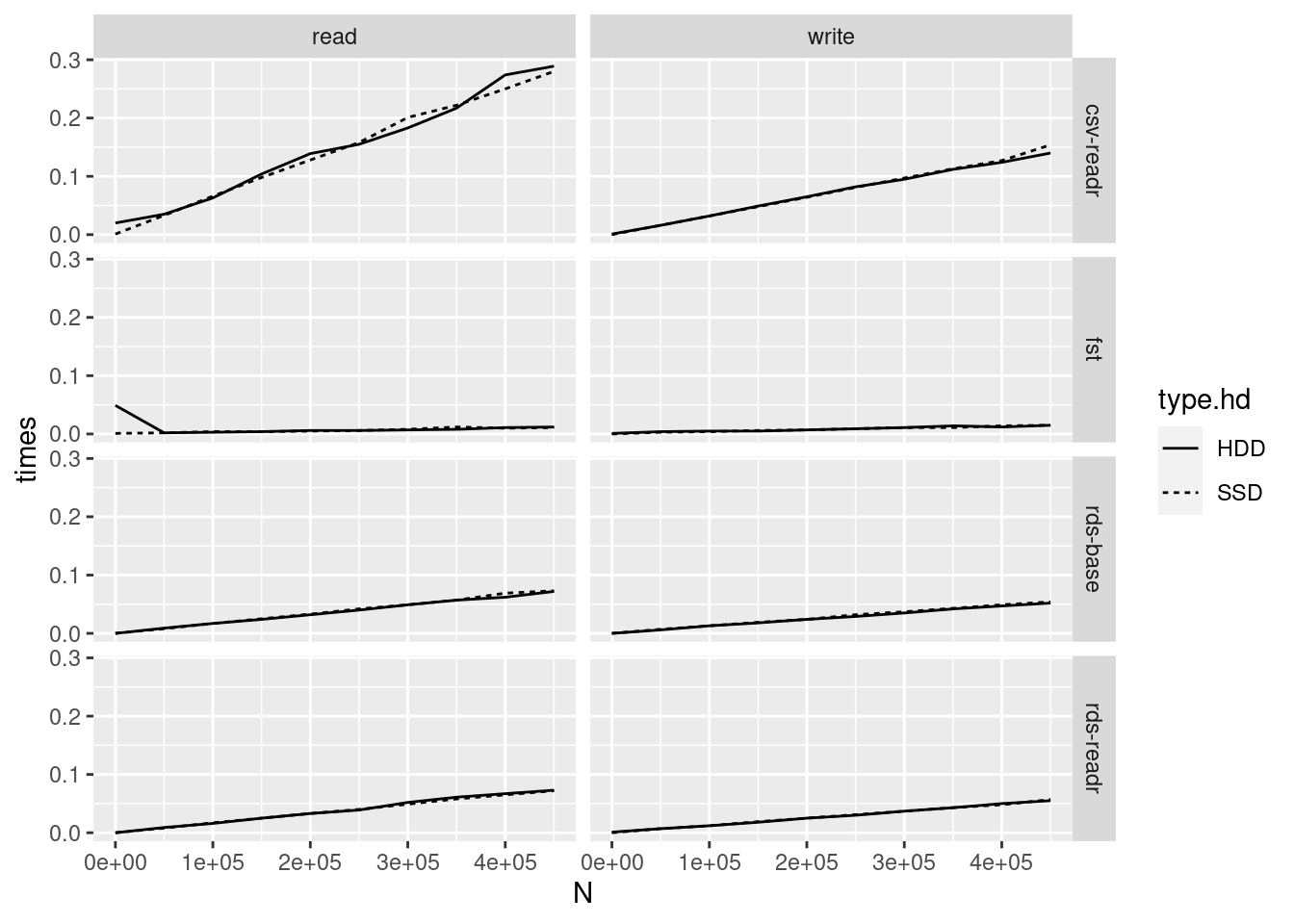
When it comes to the file format, we learn:
By far, the
fstformat is the best. It takes less time to read and write than the others. However, it’s probably unfair to compare it tocsvandrdsas it uses the 16 cores of my computer.readris a great package for writing and reading csv files. You can see a large difference of time from using thebasefunctions. This is likely due to the use of low level functions to write and read the text files.When using the rds format, the base function do not differ much from the
readrfunctions.
As for the effect of using SSD, its clear that it DOES NOT effect the time of reading and writing. The differences between using HDD and SSD looks like noise. Seeking to provide a more robust analysis, let’s formally test this hypothesis using a simple t-test for the means:
tab <- df.res %>%
group_by(type.file, type.time) %>%
summarise(mean.HDD = mean(times[type.hd == 'HDD']),
mean.SSD = mean(times[type.hd == 'SSD']),
p.value = t.test(times[type.hd == 'SSD'],
times[type.hd == 'HDD'])$p.value)
print(tab)## # A tibble: 10 x 5
## # Groups: type.file [5]
## type.file type.time mean.HDD mean.SSD p.value
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 csv-base read 0.381 0.307 0.562
## 2 csv-base write 0.457 0.453 0.981
## 3 csv-readr read 0.148 0.144 0.922
## 4 csv-readr write 0.0716 0.0732 0.942
## 5 fst read 0.0108 0.00630 0.343
## 6 fst write 0.0083 0.00800 0.890
## 7 rds-base read 0.0362 0.0373 0.921
## 8 rds-base write 0.0266 0.0278 0.882
## 9 rds-readr read 0.0375 0.0367 0.943
## 10 rds-readr write 0.0278 0.0279 0.991As we can see, the null hypothesis of equal means easily fails to be rejected for almost all types of files and operations at 10%. The exception was for the fst format in a reading operation. In other words, statistically, it does not make any difference in time from using SSD or HDD to read or write files in different formats.
I am very surprised by this result. Independently of the type of format, I expected a large difference as SSD drives are much faster within an OS. Am I missing something? Is this due to the OS being in the SSD? What you guys think?
Marcelo S. Perlin
Associate Professor
My research interests include data analysis, finance and cientometrics.